预备知识
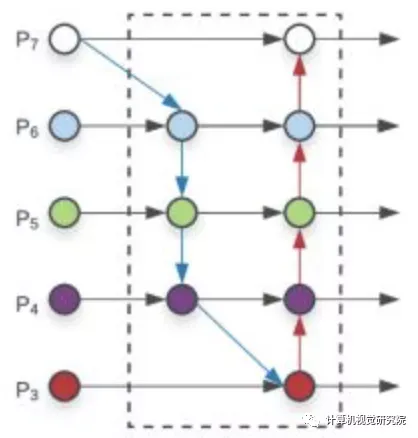
BIFPN
参考链接:Bi FPN - 知乎 (zhihu.com)
随着网络层数的加深,网络的感受野逐渐变大,语义表达能力也随之增强,但是这也使得图像的分辨率降低,很多细节特征经过多层网络的卷积操作后变得越来越模糊。浅层神经网络的感受野小,细节特征的表达能力强,但是提取的特征语义性较弱。 因此为了获得强语义性的特征,传统的目标检测模型通常只采用特征提取网络最后一层输出的特征图进行物体的分类与定位。而最后一个特征图对应的下采样率较大,一般为16、32倍下采样。这就造成小目标在最后一个特征图上的有效信息较少,小目标的检测能力降低,这被称为多尺度问题。 多尺度特征融合很好的解决了这个问题,其不再是只将最后一层的特征图用于检测,而是选择多层的特征进行融合再进行检测。
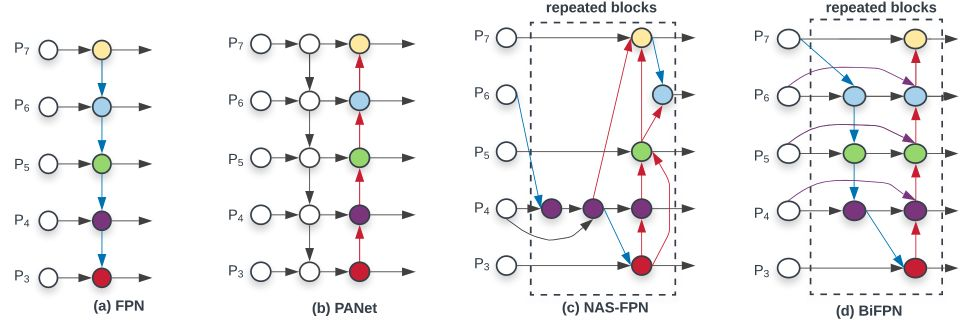
高效的多尺度特征融合 自FPN [2]引入以来,FPN已被广泛应用于多尺度特征融合。最近,PANET、NAS-FPN和其他研究开发了更多的跨尺度特征融合网络结构。在融合不同的输入特征的同时,大多数以前的工作只是不加区分地总结它们;然而,由于这些不同的输入特征具有不同的分辨率,我们观察到它们通常对融合的输出特征作出不平等的贡献。为了解决这一问题,作者提出了一个简单而高效的加权双向特征金字塔网络(BiFPN),它引入可学习的权重来学习不同输入特征的重要性,同时反复应用自顶向下和自底向上的多尺度特征融合。(本文重点探讨的问题)
在本文中,我们旨在以一种更加直观和有原则的方式优化多尺度特征融合。
模型效率在计算机视觉领域中越来越重要。作者研究了神经网络结构在目标检测中的设计选择,并提出了提高检测效率的几个关键优化方案。首先提出了一种加权双向特征金字塔网络(BiFPN) ,该网络能够方便、快速的进行多尺度特征融合。
为了提高模型的效率,该论文提出了几种跨尺度连接的优化方法:
首先 ,我们删除那些只有一个输入边的节点。我们认为:如果一个节点只有一条输入边而没有特征融合,那么它对融合不同特征的特征网络的贡献就会更小。所以我们移除了PANet中P3,P7的中间结点,这就导致了一个简化的双向网络;
其次, 我们添加一个跳跃连接,在同一尺度的输入节点到输出节点之间加一个跳跃连接,因为它们在相同层,在不增加太多计算成本的同时,融合了更多的特征。得到上图(d);
最后, 与PANet 仅有一个自顶向下和一个自底向上的路径不同,我们将每个双向(自顶向下和自底向上)路径看作一个特征网络层(repeated blocks),并多次重复同一层,以实现更高层次的特征融合。
摘要
知识蒸馏是一种将知识从预先训练好的复杂教师模型转移到学生模型的方法,因此在部署阶段,一个较小的网络可以取代一个大型的教师网络。为了减少训练大型教师模型的必要性,最近的文献引入了一种自监督知识蒸馏法,在没有预先训练的教师网络的情况下,逐步训练学生网络,提取自己的知识。自监督知识蒸馏主要分为基于数据增强的方法 和基于辅助网络的方法 ,而数据增强方法在增强过程中失去了局部信息,阻碍了其对语义分割等各种视觉任务的适用性。此外,这些知识蒸馏方法不接收在目标检测和语义分割中普遍存在的细化特征图。
本文提出了一种新的自知识精馏方法——自监督知识馏特征细化(FRSKD),该方法利用辅助自教师网络将细化后的知识传递给分类器网络(学生网络)。我们提出的方法FRSKD可以利用软标签和特征映射提取来进行自我知识蒸馏。因此,FRSKD可以应用于分类和语义分割,强调保留局部信息
该已实现的代码可以在https://github.com/MingiJi/FRSKD 上找到。
介绍
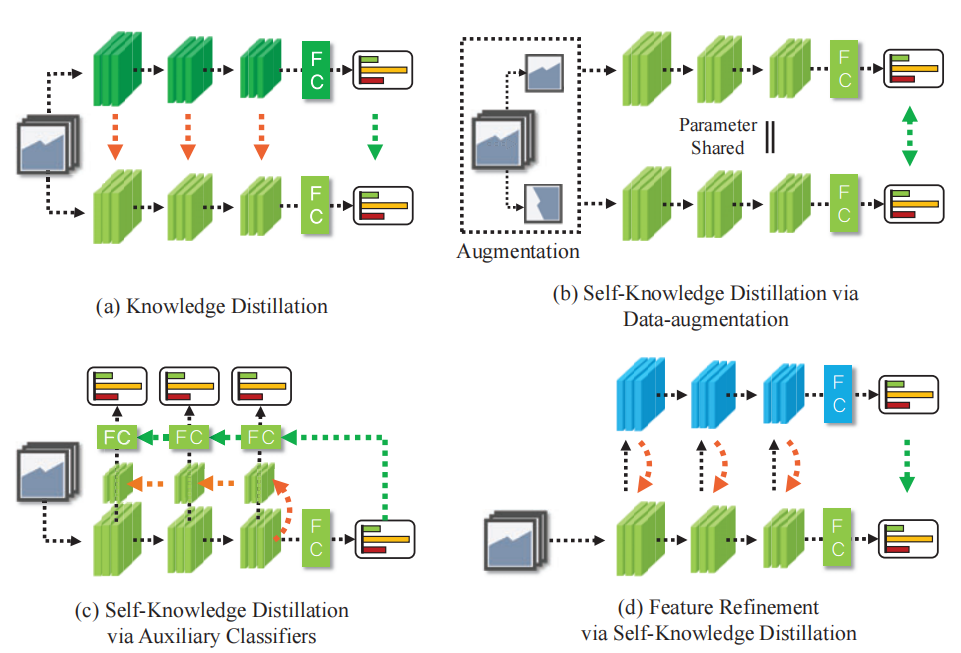
针对现有自知识精馏的局限性,提出了一种新的自知识精馏方法——自监督知识蒸馏特征细化(FRSKD),该方法引入了一种辅助自教师网络,使细化的知识能够转移到分类器网络中。图1显示了FRSKD与现有知识蒸馏方法的区别。我们提出的方法——FRSKD,可以利用软标签和特征图蒸馏进行自知识蒸馏。
图1:各种蒸馏方法的比较。黑色的线是前进的路径,绿色的线是软标签蒸馏,橙色的线是特征蒸馏。(a)传统的知识蒸馏方法与预先训练好的教师[9,26,36,14,1]。(b)自知识精馏方法通过数据增强[32,35,18]。(c)基于辅助弱分类器的自知识精馏,创建一层分类器,在每一层生成反向传播信号,从层的特征提取和绿线[39]的logit蒸馏中进行估计。(d)我们提出的方法。原始分类器提供原始特征作为辅助自我教师网络(蓝色块)的输入。然后,自教师网络将细化后的特征映射提取到原始分类器(橙色线)。
图1:各种蒸馏方法的比较。黑色的线是前进的路径,绿色的线是软标签蒸馏,橙色的线是特征蒸馏。(a)传统的知识蒸馏方法与预先训练好的教师[9,26,36,14,1]。(b)自知识精馏方法通过数据增强[32,35,18]。(c)基于辅助弱分类器的自知识精馏,创建一层分类器,在每一层生成反向传播信号,从层的特征提取和绿线[39]的logit蒸馏中进行估计。(d)我们提出的方法。原始分类器提供原始特征作为辅助自我教师网络(蓝色块)的输入。然后,自教师网络将细化后的特征映射提取到原始分类器(橙色线)。
因此,FRSKD可以应用于分类和语义分割,这是强调局部信息的保存。FRSKD显示了状态与其他自知识精馏方法相比,在不同数据集上的图像分类任务上的艺术性能。此外,FRSKD还提高了语义分割的性能。此外,FRSKD还与其他自知识精蒸馏方法以及数据增强兼容。通过各种实验,我们证明了FRSKD与大规模性能改进的兼容性。
方法
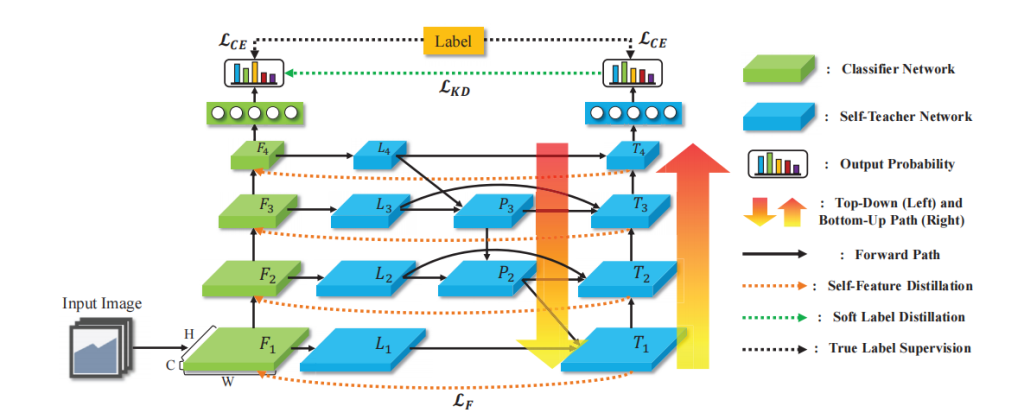
本节介绍了一个特征细化自知识精馏(FRSKD)。图2显示了我们的蒸馏方法的概述,并将在第3.1节中从自我教师网络的角度进行进一步讨论。然后,我们在第3.2节中回顾了我们的自认识精馏的训练过程。
图2:我们提出的自知识精馏方法的概述,通过自知识精馏(FRSKD)进行特征细化。自顶向下路径和自下而上路径聚合了不同大小的特征,并为原始分类器网络提供了细化的特征映射。FRSKD利用自教师网络的特征图,对精细化的特征图和软标签进行精馏。
图2:我们提出的自知识精馏方法的概述,通过自知识精馏(FRSKD)进行特征细化。自顶向下路径和自下而上路径聚合了不同大小的特征,并为原始分类器网络提供了细化的特征映射。FRSKD利用自教师网络的特征图,对精细化的特征图和软标签进行精馏。 3.1. Self-Teacher Network
自教师网络的主要目的是为分类器网络自身提供一个精细化的特征图及其软标签。自教师网络的输入是分类器网络的特征映射,F1,…,Fn,它假定分类器网络的n个块。我们通过修改BiFPN的结构来建模自我教师网络。具体来说,我们采用了PANet和BiFPN [28,20]的自顶向下路径和自下而上路径。在自上而下的路径之前,我们使用横向卷积层如下:
Conv是一个输出维数为di的卷积运算。与现有的固定在网络设置上的横向卷积层不同,我们设计的依赖于特征图的通道维度ci。。对于分类任务,很自然地为更深的层设置更高的信道维度。因此,我们调整每一层的通道尺寸,以包含其特征图深度的信息。此外,这种设计减少了横向层的计算。
自顶向下路径和自底向上路径聚合不同特征如下所示:
Pi表示自上向下路径的第i层;Ti是自底向上路径的第i层。与BiFPN [28]类似,前通连接根据层的不同深度有不同的结构。在图2中,在最浅的自下而向上路径层T1和最深的自底向上路径层T4的情况下,每个路径层都分别直接利用横向层L1和L4作为效率的输入,而不是使用自上而下路径的特征。在这些设置中,为了创建一个连接最顶向下的结构,连接所有最浅层、中间层和最深层,添加了两个用于正向传播的对角线连接: 1)从最后一个横向层L4到自顶向下路径的倒数第二层P3的连接;2)从P2到自底向上路径的第一层T1的连接。
我们应用一个快速归一化融合的参数,如wP和w T [28]。我们使用双线性插值来进行上采样,并使用最大池化来进行下采样,作为调整大小算子。为了进行有效的计算,我们在卷积运算中使用深度卷积[11]。我们根据第4.3节中的自我教师网络结构,进行了各种实验,并对结果进行了分析。最后,我们在自底向上路径的顶部附加全连接层来预测输出类,自教师网络提供其软标签,pˆt=softmax(ft(x;θt)),其中ft表示由θt参数化的自教师网络。
3.2 Self-Feature Distillation
我们提出的模型,FRSKD,利用了自我教师网络的输出,改进的特征图,Ti,和软标签,pˆt。首先,我们添加了特征蒸馏法,从而诱导分类器网络来模拟改进后的特征图。对于特征提取,我们采用了注意力转移[36]。公式3定义了特征蒸馏损失,LF:
其中,φ是信道池化函数与L2归一化[36]的组合;θc是分类器网络的参数。φ抽象出了特征图的空间信息。因此,LF使分类者网络从自教师网络中学习细化后的特征映射的局部性。此外,还可以训练一个分类器网络来精确地模拟改进后的特征图[26,8];或者利用特征图[34]的变换。除非特别说明,本文利用了基于注意力转移的特征蒸馏,并在第4.3节中讨论了特征蒸馏的方法。
与其他自知式蒸馏方法类似,FRSKD也通过软标签pˆt进行蒸馏,如下:
其中,fc为分类器网络,K为温度尺度参数。此外,分类器网络和自教师网络使用交叉熵损失,LCE学习地面真实标签。通过积分上述的损失函数,
我们构建了以下优化目标:
其中α和β是超参数;我们选择了α∈[1,2,3]和β∈[100,200];进一步的细节在附录敏感性分析中解释。对于分类器网络和自教师网络,优化都是通过反向传播同时发起的。为了防止模型崩溃问题[22],FRSKD通过蒸馏损失、LKD和LF来更新参数,这只应用于学生网络。
loss组成包括三个部分:1)同级特征图之间的蒸馏(对特征图进行了channel-wise pooling);2)原始分类网络末端与self-teacher末端softmax层之间的KL散度蒸馏; 3)原始分类网络、self-teacher分别于label之间的蒸馏
实验
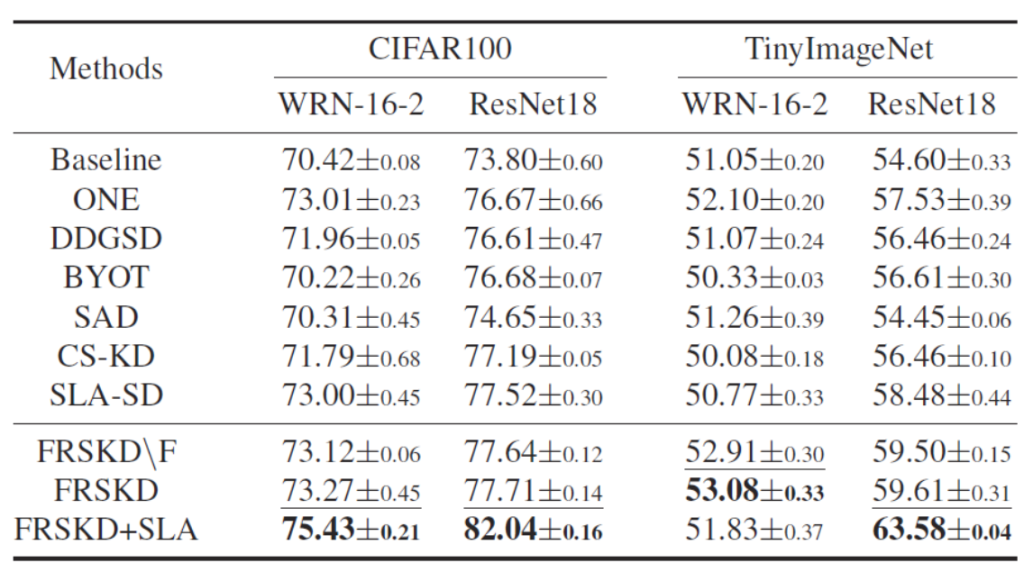
分类实验 中与其他方法间的对比。算法在多个公开数据集上进行了测试,这里只列举了部分
可以看出,算法即便是在去除Feature级别的监督情况下(FRSKD\F),依然取得了更好的性能。在加入SLA自监督策略[6]后,效果提升更加明显。
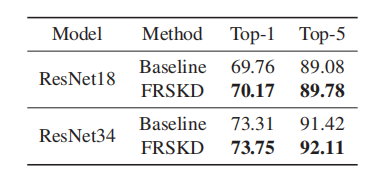
分割实验中对比 (在实验中,我们堆叠了三层BiFPN,并增加了两层作为自助教师网络)
注意力map可视化
可以看出,相对于主要的classifier,self-teacher产生的注意力能够更好得聚焦到目标最具有辨识度得区域。









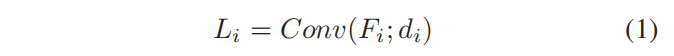
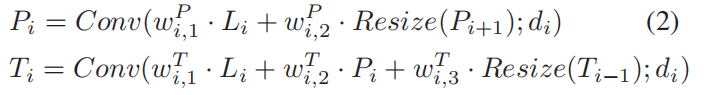
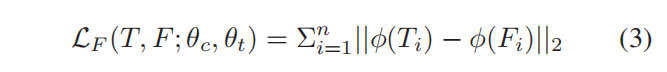
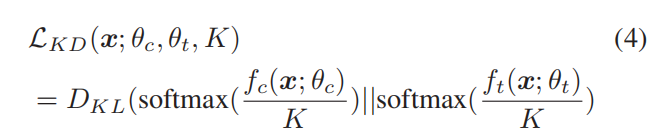
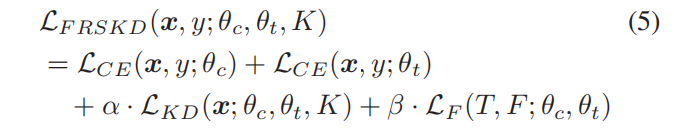




Comments | NOTHING