前导知识
(一)、为什么有标签平滑正则化(Label Smoothing Regularization, LSR)的方法?
在深度学习样本训练的过程中,我们采用one-hot标签去进行计算交叉熵损失时,只考虑到训练样本中正确的标签位置(one-hot标签为1的位置)的损失,而忽略了错误标签位置(one-hot标签为0的位置)的损失。这样一来,模型可以在训练集上拟合的很好,但由于其他错误标签位置的损失没有计算,导致预测的时候,预测错误的概率增大。为了解决这一问题,标签平滑的正则化方法便应运而生。
(二)、标签平滑是如何实现的?
(1). 传统的softmax公式如下:
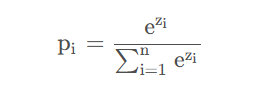
则我们可以得到交叉熵(cross entropy)损失:
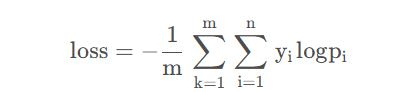
通过上面两个公式,我们可以很轻松的得到m个样本的损失。
(2). 那么有标签平滑的损失计算与没有标签平滑的损失计算具体有什么区别呢?
先举个没有标签平滑计算的例子
Example1:假设有一批样本,样本类别总数为5,从中取出一个样本,得到该样本的one-hot化后的标签为[ 0 , 0 , 0 , 1 , 0 ],假设我们已经得到了该样本进行softmax的概率矩阵p,
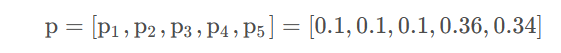
则我们可以求得当前单个样本的loss,即
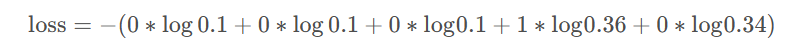
计算结果为1.47。
可以发现没有标签平滑计算的损失只考虑正确标签位置的损失,而不考虑其他标签位置的损失,这就会出现一个问题,即不考虑其他错误标签位置的损失,这会使得模型过于关注增大预测正确标签的概率,而不关注减少预测错误标签的概率,最后导致的结果是模型在自己的训练集上拟合效果非常良好,而在其他的测试集结果表现不好,即过拟合,也就是说模型泛化能力差。
(3). 再举一个标签平滑的例子
Example2:假设还是上面那批样本,样本类别总数仍为5,我们还是取出刚才的那个样本,得到该样本的one-hot化后的标签为[ 0 , 0 , 0 , 1 , 0 ] ,仍假设我们已经得到了该样本进行softmax的概率矩阵p,即p = [ p 1 , p 2 , p 3 , p 4 , p 5 ] = [ 0.1 , 0.1 , 0.1 , 0.36 , 0.34 ] ,对于进行标签平滑该怎么做呢?我们先设一个平滑因子为ϵ = 0.1,进行如下平滑:

y就是我们经过平滑操作后得到的标签,接着我们就可以求平滑后该样本的交叉熵损失了。
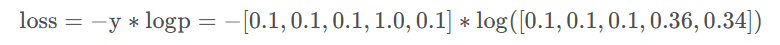
计算结果为loss=2.63。
此时可以看出,平滑过后的样本交叉熵损失就不仅考虑到了训练样本中正确的标签位置(one-hot标签为1的位置)的损失,也稍微考虑到其他错误标签位置(one-hot标签为0的位置)的损失,导致最后的损失增大,导致模型的学习能力提高,即要下降到原来的损失,就得学习的更好,也就是迫使模型往增大正确分类概率并且同时减小错误分类概率的方向前进。
(三)、标签平滑的公式
假设y为当前样本one-hot后的标签,则标签平滑公式可表述为:

(四)、总结
标签平滑的实质就是促使神经网络中进行softmax激活函数激活之后的分类概率结果向正确分类靠近,即正确的分类概率输出大(对应的one-hot标签为1位置的softmax概率大),并且同样尽可能的远离错误分类(对应的one-hot标签为0位置的softmax概率小),即错误的分类概率输出小。
Abstract
知识蒸馏(KD)的目的是将一个繁琐的教师模型的知识提炼成一个轻量级的学生模型。它的成功通常归因于教师模式提供的类别间相似性的特权信息,在这个意义上,只有强大的教师模式被部署到在实践中教授较弱的学生。在这项工作中,我们通过以下实验观察来挑战这一普遍的信念:
- 除了承认教师可以提高学生水平之外,学生还可以通过逆转KD程序来显著提高教师水平;
- 训练不足的教师,准确率比学生低得多,仍然可以显著提高后者。
为了解释这些观察结果,我们提供了一个关于KD和标签平滑正则化之间的关系的理论分析。我们证明了
- KD是一种学习过的标签平滑正则化
- 标签平滑正则化为KD提供了一个虚拟的教师模型。
从这些结果来看,我们认为KD的成功并不是完全是因为来自教师的类别之间的相似性信息,而是由于软目标的正则化,这同样重要,甚至更重要。在此分析的基础上,我们进一步提出了一种新的无教师知识蒸馏(Tf-KD)框架,在该框架中,学生模型从自身中学习或手动设计的正则化分布。Tf-KD取得了与来自优秀教师的正常KD相当的性能,这在没有更强的教师模式时得到了很好的应用。同时,Tf-KD是一种通用的方法,可以直接部署用于深度神经网络的训练。在没有任何额外的计算成本的情况下,Tf-KD在ImageNet上比已建立的基线模型实现了高达0.65%的改进,这优于标签平滑正则化。
1. Introduction
知识蒸馏(KD)[7]的目标是将知识从一个神经网络(教师)转移到另一个神经网络(学生)。通常,教师模式具有较强的学习能力和较高的表现,这是通过提供“软目标”来教授较低能力的学生模式。人们普遍认为,教师模型的软目标可以传递包含不同类别[7]之间相似性特权信息的“暗知识”,以增强学生模型。
在这项工作中,我们首先通过以下探索性实验来检验这种普遍的信念:
- 让学生模型通过转移学生的软目标来教授教师模型;
- 让训练较差、表现较差的教师模型教学生。
基于普遍的信念,预计教师模型不会通过学生的培训得到显著增强,训练不足的教师不会增强学生,因为薄弱的学生和训练不足的教师模型不能提供类别间可靠的相似性信息。然而,经过在各种模型和数据集上的广泛实验,我们观察到矛盾的结果:弱的学生可以提高教师,训练不足的教师也可以显著提高学生。这些有趣的结果促使我们将KD解释为一个正则化术语,我们从标签平滑正则化(LSR)[16]的角度重新检查知识蒸馏,该[16]通过用平滑的标签替换单热标签来使模型训练正则化。
然后从理论上分析了KD和LSR之间的关系。LSR,通过将平滑标签分为两部分,检查相应的损失,我们发现第一部分是普通的交叉熵ground-truth分布(one-hot label))和标签和输出模型,第二部分对应于一个虚拟教师模型提供了一个均匀分布来教模型。对于KD,通过将教师的软目标与一个热门的ground-truth标签相结合,我们发现KD是一个学习的LSR,其中KD的平滑分布来自一个教师模型,但LSR的平滑分布是手工设计的。简而言之,我们发现KD是一个学习的LSR,LSR是一个特别的KD。这种关系可以解释上述违反直觉的结果——来自弱学生和缺乏训练的教师模型的软目标可以有效地解释规范模型训练,即使它们在类别之间缺乏很强的相似性信息。因此,我们认为类别间的相似性信息并不能完全解释KD中的黑暗知识,而来自教师模型的软目标确实为学生模型提供了有效的正则化,这同样重要,甚至更重要。
基于这些分析,我们推测,在教师模型中类别间相似性信息不可靠甚至为零的情况下,KD仍然可以很好地改进学生模型。因此,我们提出了一种新的无教师知识提炼(Tf-KD)框架,有两种实现。第一个是自行训练学生模型(即自我训练),第二个是手动设计一个目标分布,作为一个具有100%准确率的虚拟教师模型。第一种方法的动机是用模型本身的预测取代黑暗知识,第二种方法的灵感来自于KD和LSR之间的关系。我们通过大量的实验验证了Tf-KD的两种实现都是简单而有效的。特别是在虚拟教师中没有相似性信息的第二个实现中,Tf-KD仍然取得了与正常KD相当的性能,这清楚地证明:
黑暗知识不仅包括类别之间的相似性,而且还对学生的训练进行了正规化。
Tf-KD适用于学生模型过于强大而无法找到教师模型的情况,或者用于培训教师模型的计算资源有限的情况。例如,如果我们使用一个笨重的单一模型ResNeXt10132×8d[18]作为学生模型(在ImageNet上具有88.79M参数和16.51G FLOPs),那么训练一个更强大的教师模型就很困难,或者在计算上很昂贵。我们部署了我们的虚拟老师来教这个强大的学生,在没有任何额外计算成本的情况下,在ImageNet上实现了0.48%的改进。同样,以功能强大、参数34.53M的单模型ResNeXt29-8×64d作为学生模型,我们的自训练实现在CIFAR100上实现了1.0%以上的提高(从81.03%提高到82.08%)。
我们的贡献总结如下:
- 通过设计两个关于KD教师模型的探索性实验,我们观察到违反直觉的结果,这促使我们将KD解释为一种正则化方法。
- 然后我们提供理论分析来揭示KD和标签平滑正则化之间的关系。
- 我们提出了免费教师知识蒸馏(TfKD),它实现了与普通知识蒸馏相比的性能,并在ImageNet2012上实现了标签平滑正则化的优越性能。
2. 探索性实验和反直觉的观察
为了检验KD对黑暗知识的普遍信念,我们进行了两个探索性实验:
- 标准的知识提炼是请老师去教较弱的学生。如果我们逆转操作呢?一般认为,教师不应该因为学生太弱而显著提高有效知识的传递。
- 如果我们用一个训练不佳的老师来教学生,他的表现比学生差得多,就会认为后者不会有任何改善。例如,在一个图像分类任务中,如果采用一个训练不佳,准确率只有10%的教师,那么学生就会从其准确率为90%的软目标中学习,因此学生的表现不会得到提高,甚至会更差。
我们将“学生授课教师”命名为反向知识蒸馏(Re-KD),将“缺乏培训的教师授课学生”命名为缺陷知识蒸馏(De-KD)(图1)。我们使用各种神经网络在CIFAR10、CIFAR100和Tiny-ImageNet数据集上进行了Re-KD和De-KD实验。为公平比较,所有实验均采用相同的设置,并对70个epoch训练(共200个epoch)进行网格搜索获得超参数。详细的实施和实验设置在补充材料中给出。

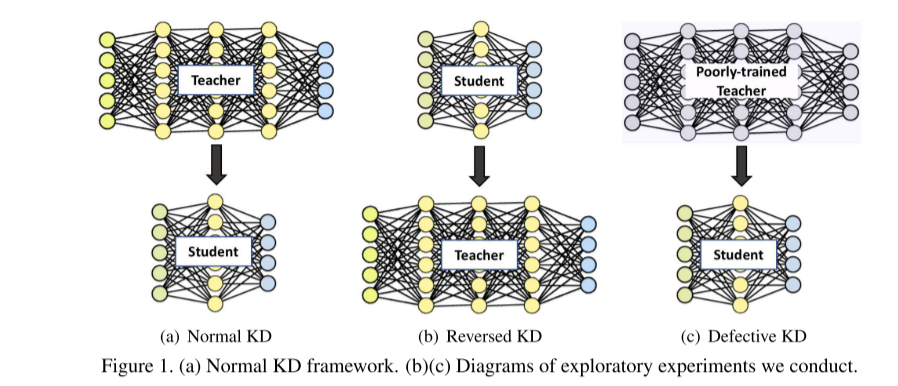
2.1. Reversed Knowledge Distillation
我们分别对这三个数据集进行了Re-KD实验。CIFAR10和CIFAR100[9]包含32 × 32像素的自然RGB图像,分别具有10和100个类,而Tiny-ImageNet是ImageNet[3]的子集,具有200个类,其中每个图像被缩小到64x64像素。为了实验的通用性,我们采用5层普通CNN、MobilenetV2[15]和ShufflenetV2[10]作为学生模型,ResNet18、ResNet50[6]、DenseNet121[8]和ResNeXt29-8×64d作为教师模型。3个数据集的Re-KD结果见表1 ~表3。
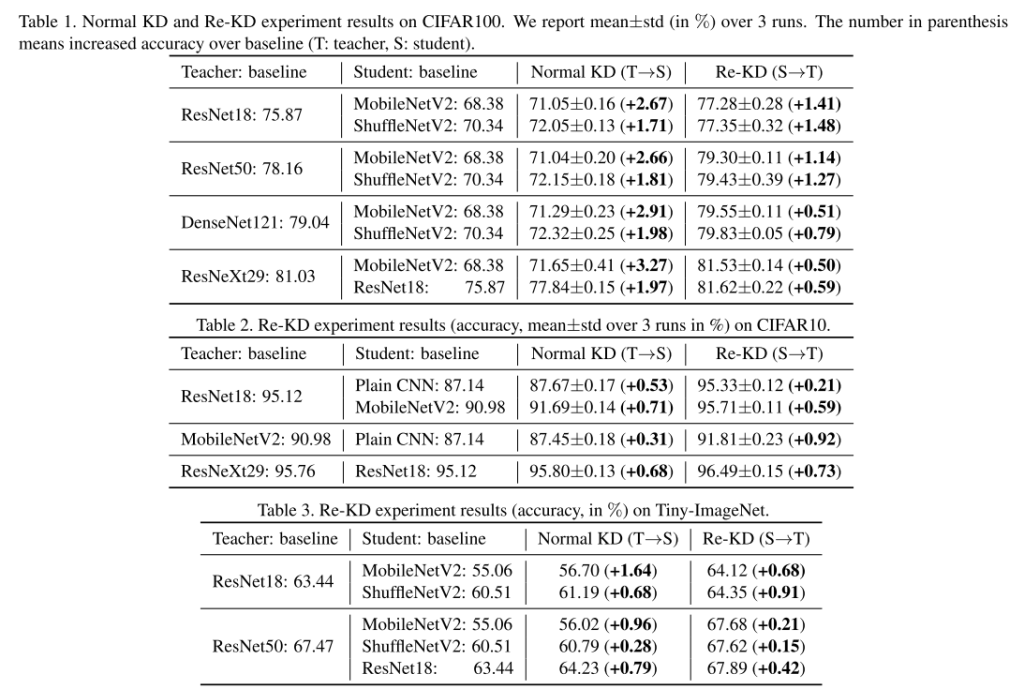
在表1中,教师模型通过学生的学习得到了显著的改进,尤其是教师模型ResNet18和ResNet50。在使用MobileNetV2和ShuffleNetV2进行教学时,两位教师的进步都在1.1%以上。我们也可以在CIFAR10和Tiny-ImageNet上观察到类似的结果。比较Re-KD时(S→T)与KD Normal (T→S),我们可以看到在大多数情况下,KD Normal的效果更好。值得注意的是,Re-KD以教师的准确性为基准,其准确性远远高于Normal KD。然而,在某些情况下,我们可以发现Re-KD优于Normal KD。例如,在表2(第三行)中,学生模型(普通CNN)在使用MobileNetV2教学时只能提高0.31%,而教师(MobileNetV2)通过向学生学习可以提高0.92%。我们对ResNeXt29和ResNet18也有类似的观察(表2第4行)。
我们认为,尽管标准的知识提炼可以提高学生在所有数据集上的表现,但优秀的教师也可以通过从弱学生身上学习显著提高,正如Re-KD实验所表明的那样。
2.2. Defective Knowledge Distillation
我们在CIFAR100和Tiny-ImageNet上进行De-KD。我们采用MobileNetV2和ShuffleNetV2作为学生模型,ResNet18、ResNet50和ResNeXt29 (8×64d)作为教师模型。培训较差的教师受1 epoch (ResNet18)或50 epoch (ResNet50和ResNeXt29)的培训,表现很差。例如,ResNet18用1 epoch训练后,在CIFAR100上的准确率仅为15.48%,在Tiny-ImageNet上的准确率为9.41%;ResNet50用50个epoch(共200个epoch)训练后,在CIFAR100和Tiny-ImageNet上的准确率分别为45.82%和31.01%。
从表4中CIFAR100的De-KD实验结果中,我们可以观察到,即使是在训练不足的教师的蒸馏下,学生也能得到很大的提升。例如,MobileNetV2和ShuffleNetV2可以提升2.27%和1.48%,当一个时代训练ResNet18只有15.48%的准确率(第二行)。对于训练较差的ResNeXt29,准确率为51.94%(第四行),我们发现ResNet18仍然可以提高1.41%,而MobileNetV2提高了3.14%。从表4中Tiny-ImageNet上的De-KD实验结果,我们发现ResNet18准确率为9.14%,仍能将教师模型MobileNetV2提高1.16%。其他缺乏培训的老师都能在一定程度上提高学生的能力。
为了更好地展示一个学生在接受不太熟练且精度水平不同的教师教学时的蒸馏蒸馏,我们在正常的训练过程中保存了ResNet18和ResNeXt29的9个检查站。将这些检查点作为教师模型来教授MobileNetV2,我们观察到MobileNetV2总是可以通过训练不充分的ResNet18或训练不充分的ResNeXt29以不同的准确性水平得到改进(图2)。因此我们可以说,当一个训练不充分的教师为学生提供更多的噪声logits时,学生仍然可以得到增强。De-KD实验的结果也与普遍的信念相冲突。
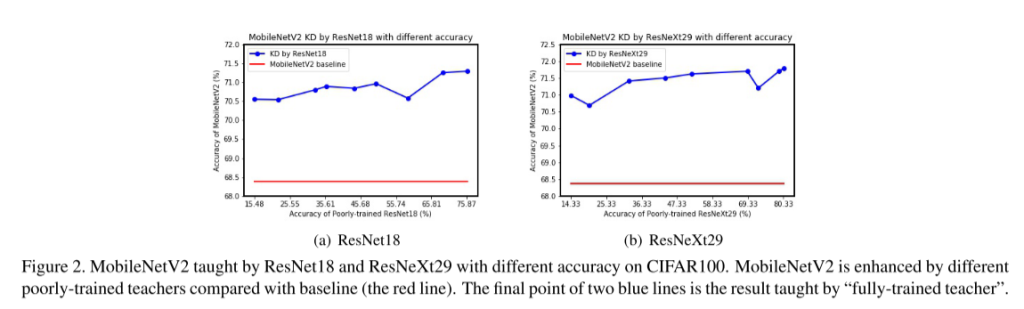
Re-KD和De-KD的反直觉结果使我们重新思考KD中的“黑暗知识”,我们认为它不仅仅包含相似信息。由于缺乏足够的相似信息,一个模型仍然可以提供“黑暗知识”来增强其他模型。为了解释这一点,我们做了一个合理的假设,将知识蒸馏看作是模型正则化,并研究模型的“黑暗知识”中有什么附加信息。接下来,我们将分析知识蒸馏和标记平滑正则化之间的关系,来解释Re-KD和De-KD的实验结果。
3. Knowledge Distillation and Label Smoothing Regularization
我们用数学方法分析了知识蒸馏(KD)和标签平滑正则化(LSR)之间的关系,希望能够解释第2节中探索性实验的有趣结果。给定一个神经网络S进行训练,我们首先给出S的LSR的损失函数。对于每个训练例子x, S输出每个标签的概率
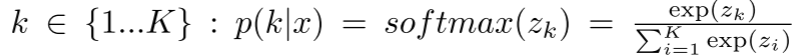
其中zi是神经网络S的logit。Ground Truth标签上的分布是q(k|x)。为了简单起见,我们把p(k|x)写成p(k) q(k|x)写成q(k)通过最小化交叉熵损失来训练模型S。对于单一的ground-truth标签y, q(y|x) = 1, q(k|x) = 0对于所有k≠y。
在LSR中,最小化了修正标签分布q ' (k)与网络输出p(k)之间的交叉熵,其中,q ' (k)为平滑的标签分布,表示为:
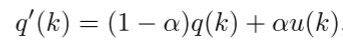
它是q(k)和固定分布u(k)的混合物,权值为α。通常u(k)是均匀分布的,u(k) = 1/ k。定义在平滑标签上的交叉熵损失H(q ', p)为:
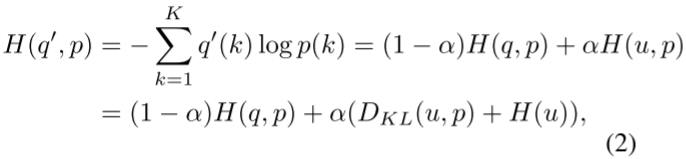
式中,DKL为Kullback-Leibler散度(KL散度),H(u)为u的熵,为固定均匀分布u(k)的常数。因此,标签平滑对模型S的损失函数可以写成:
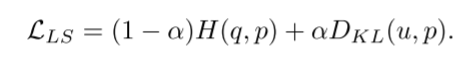
在知识蒸馏方面,运用师生学习机制来提高学生的表现。假设学生为模型S,输出预测为p(k),教师网络的输出预测为:
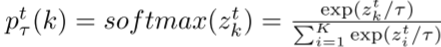
式中zt为教师网络的输出对数,τ为软化pt(k)的温度(表示软化后的pt τ(k))。知识蒸馏背后的思想是让学生(模型S)通过最小化学生和教师预测之间的交叉熵损失和KL散度来模仿教师:
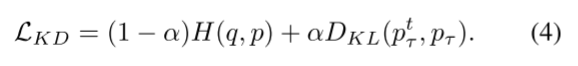
比较Eq.(3)和Eq.(4),我们发现这两个损失函数具有相似的形式。唯一的区别是,DKL(pt τ, pτ)中的pt τ(pt τ, pτ)是来自教师模型的分布,而DKL(u, p)中的u(k)是预定义的均匀分布。从这个角度来看,我们可以把KD看作是flsr的一种特殊情况,其中平滑分布是学习而不是预先定义的。另一方面,如果我们将正则化项DKL(u, p)看作是知识提炼的虚拟教师模型,这个教师模型将给所有班级一个均匀的概率,这意味着它具有随机的准确性(CIFAR100为1%的准确性,ImageNet为0.1%的准确性)。
由于DKL(pt τ, pτ) = H(pt τ, pτ) - H(pt τ),其中对于固定的教师模型,熵H(pt τ)是常数,因此,我们可以将式(4)改写为
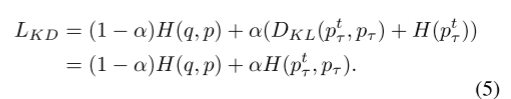
若设置温度τ = 1,则有LKD = H(qt, p),其中qt为
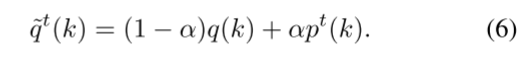
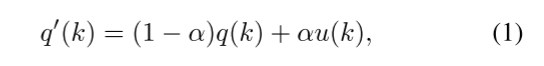
将式(6)与式(1)进行比较,可以更清楚地看出KD是LSR的一种特殊情况。此外,分布pt(k)是一个学习分布(来自受过培训的教师),而不是均匀分布u(k)。我们将教师的输出概率pt(k)可视化,并将其与补充材料中的标签平滑进行比较,发现当τ温度较高时,pt(k)更接近于标签平滑的均匀分布u(k)。
通过对两种损失函数的比较,我们总结出知识蒸馏与标签平滑正则化的关系如下:
- 知识蒸馏是一种经过学习的标签平滑正则化,它与后者具有相似的功能,即正则化模型的分类器层。
- 标签平滑是一种特殊的知识蒸馏,可以作为一个具有随机精度且温度τ = 1的教师模型来重新考察。
- 温度越高,教师在知识蒸馏过程中的软目标分布越接近标签平滑时的均匀分布。
因此,Re-KD和De-KD的实验结果可以解释为模型在高温下的软目标更接近均匀分布的标签平滑,学习到的软目标可以为教师模型提供模型正则化。这就是为什么一个学生可以提高老师的能力,而一个缺乏训练的老师仍然可以改进学生的模式。
4.Teacher-free Knowledge Distillation
如前所述,教师模型中的“暗知识”更多的是一个正则化术语,而不是类别间的相似信息。直观上,我们考虑用一个简单的输出分布来代替教师模型。因此,我们提出了一个新的Tf-KD框架,该框架有两个实现。Tf-KD特别适用于没有更强的教师模型,或只提供有限的计算资源的情况。
第一个Tf-KD方法是自我训练知识蒸馏,记作Tf-KDself。正如前面提到的,老师可以由一个学生来教,一个缺乏训练的老师也可以提高学生。因此,当没有更强大的教师模式时,我们建议采用“自我培训”。值得注意的是,KD老师总是意味着一个更强的模型。我们称自我训练为一种无老师的方法,因为这种模式并不是老师比自己的学习能力更强。我们的Tf-KDself类似于重生网络[4],但有两个区别。我们的动机(自我训练/自我规范)不同于重生网络;我们的方法使用模型自的软目标作为正则化,而Bornagain网络使用学生模型的集合进行迭代训练。具体来说,我们首先以正常的方式训练学生模型,获得一个预训练模型,然后使用该模型提供软标签来训练自身,如式(4)所示。形式上,给定一个模型S,我们将其预训练模型表示为Sp;然后利用Tf-KDself最小化S和Sp之间对数的KL散度。Tf-KDself训练模型S的损失函数为
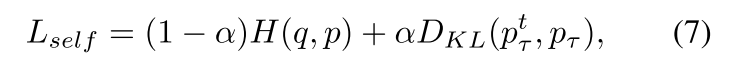
其中p, pt τ分别为S和Sp的输出概率,τ为温度,α为权值。
我们的Tf-KD方法的第二个实现是手动设计一个100%准确的教师。在第3节中,我们发现LSR是一个具有随机准确性的虚拟教师模型。所以,如果我们设计一个准确率更高的老师,我们可以假设它会给学生带来更多的进步。我们建议结合KD和LSR构建一个简单的教师模型,该模型将课堂输出分配如下:
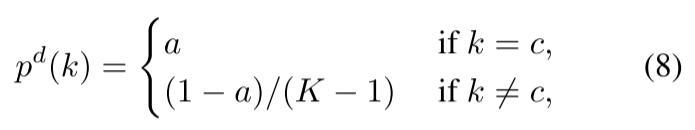
其中K是类的总数,c是正确的标签,a是正确类的正确概率。我们的设置总是≥0.9,所以正确类的概率远大于错误类的概率,并且手工设计的教师模型对于任何数据集都有100%的准确率。
我们通过手工设计正则化将此方法命名为教师自由KD方法,记作Tf-KDreg。损失函数为
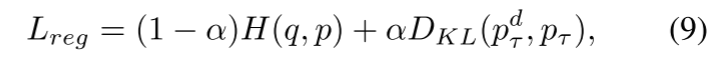
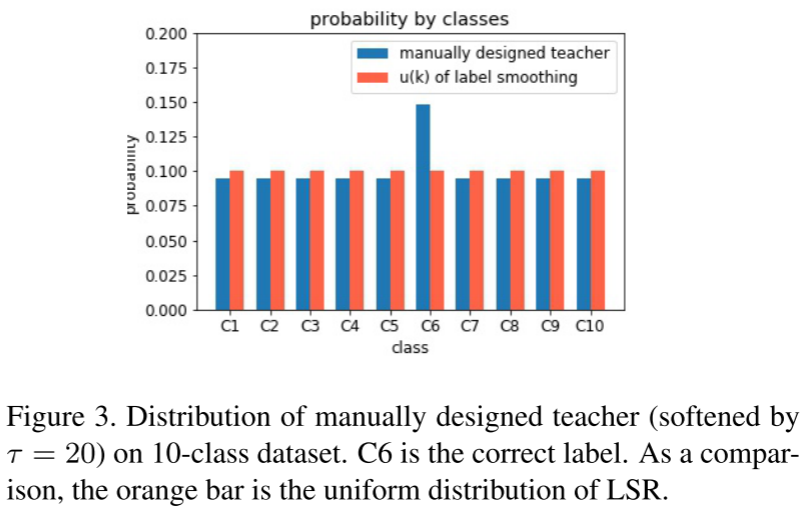
其中τ为软化人工设计分布pd的温度(软化后为pd τ)。我们设置高温τ≥20,使虚拟教师输出软概率,从而获得LSR平滑特性。我们将手工设计的教师的分布形象化如图3所示。如图3所示,该手工设计的教师模型输出的软目标分类准确率为100%,同时具有标签平滑的平滑特性。但Tf-KDreg并不是LSR的过参数化版本,因为温度τ≫1,因此当我们调整参数α、a或u(k)时,式9将不等于式3。
Tf-KDself和TfKDreg这两种免教师方法非常简单有效,下一节将通过大量实验进行验证。
5.Experiments on Tf-KD
在本节中,我们对TfKDself和Tf-KDreg在CIFAR100, Tiny-ImageNet和ImageNet这三个用于图像分类的数据集进行了实验。为了进行公平的比较,所有的实验都在相同的设置下进行。
详情见论文
Conclusion
通过实验和分析,我们发现教师模型中的“黑暗知识”更多的是一种正则化术语,而不是类别的相似信息。基于KD与LSR之间的关系,我们提出了无教师KD。实验结果表明,该方法能在图像分类中取得与常规KD方法相当的效果。我们的工作还表明,当一个强大的模型很难找到一个更强的教师,或者计算资源限制教师模型的训练时,目标模型仍然可以通过自训练或手工设计正则化项来增强。











Comments | NOTHING