Abstract
将软目标作为硬目标的加权平均和标签上的均匀分布,通常可以显著提高多类神经网络的泛化和学习速度。用这种方法平滑标签可以防止网络变得过于自信,标签平滑已经被应用到许多最先进的模型中,包括图像分类、语言翻译和语音识别。尽管标签平滑被广泛使用,但人们对它的理解仍然很差。在这里,我们的经验表明,除了提高泛化,标签平滑改善模型校准,这可以显著提高波束搜索。然而,我们也观察到,如果用标签平滑来训练教师网络,知识蒸馏到学生网络的效率会低得多 。为了解释这些观察结果,我们将标签平滑如何改变网络倒数第二层学习的表示形式可视化。我们证明了标签平滑鼓励了从同一个类到紧密聚类中的组的训练例子的表示。这将导致日志中关于不同类别实例之间相似性的信息丢失,这是蒸馏所必需的,但不会损害模型预测的泛化或校准。
1 Introduction
众所周知,神经网络训练对最小化的损失非常敏感。在Rumelhart等人对二次损失函数推导出反向传播后不久,几位研究人员指出,通过梯度下降最小化交叉熵,可以获得更好的分类性能和更快的收敛速度[2,3]。然而,即使在神经网络研究的早期,也有迹象表明,其他更奇特的目标可以优于标准的交叉熵损失[4,5]。最近,Szegedy等人。[6]引入了标签平滑,通过计算交叉熵来提高精度,而不是与“硬”目标的数据集,而是这些目标的加权混合均匀分布。
标签平滑已成功用于提高深度学习模型在一系列任务中的准确性 ,包括图像分类、语音识别、和机器翻译(表1)。Szegedy等人最初提出标签平滑作为一种策略,以改善Inception架构在ImageNet数据集上的性能,自那时以来,许多最先进的图像分类模型都将标签平滑纳入到训练过程中[7,8,9]。在语音识别中,Chorowski和Jaitly[10]使用标签平滑来降低华尔街日报数据集上的错误率。在机器翻译中,Vaswani et al.[11]在BLEU得分上取得了微小但重要的提高,尽管困惑度有所降低。
虽然标签平滑是一种被广泛使用的提高网络性能的“技巧”,但是关于标签平滑为什么以及何时应该工作,我们所知甚少。 这篇论文试图阐明神经网络训练的行为与标签平滑 ,我们描述了几个有趣的性质,这些网络。我们的贡献如下:
本文介绍了一种基于倒数第二层激活的线性投影的可视化方法。这种可视化可以直观地了解使用和不使用标签平滑训练的网络的倒数第二层之间的表示有何不同。 我们证明,标签平滑隐式校准学习模型,使其预测的置信度与预测的准确性更一致。 我们发现,标签平滑会损害蒸馏,即当教师模型使用标签平滑进行训练时,学生模型的表现更差。我们进一步表明,这种不利影响是由于logits中的信息丢失造成的。 1.1 Preliminaries
在描述我们的发现之前,我们提供了标签平滑的数学描述。假设我们将神经网络的预测写成倒数第二层激活的函数为:
其中pk是模型赋给第k类的可能性,wk代表最后一层的权值和偏差,x是包含与“1”连接的神经网络的倒数第二层的激活量的向量。对于用硬目标训练的网络,我们最小化真实目标yk与网络输出pk之间的交叉熵的期望值,如:
其中yk为“1”表示正确的类,其余类为“0”。对于参数α的标记平滑训练的网络,我们代之以最小化修改目标yLS k与网络输出pk之间的交叉熵,其中:
2 Penultimate layer representations
使用标签平滑的网络训练鼓励正确类的logit和错误类的logit之间的差异是一个依赖于α的常数。 相比之下,使用硬目标训练网络通常会导致正确的日志比任何错误的日志都要大得多,并且允许错误的日志彼此之间非常不同。直观地说,第k类的logit xTwk可以被认为是倒数第二层x的激活和模板wk之间欧几里德距离的平方的度量
在这里,每个类都有一个模板wk, xTx在计算softmax输出时被分解出来,wT k wk通常是跨类的常量。因此,标签平滑促进了倒数第二层的激活,使其与正确类的模板更接近,而与不正确类的模板距离同样远。
也就是说,当x距离某个分类 K 的模板距离更近时,x属于 K 分类的概率就越大。从这个角度看,LS鼓励x接近正确类别的模板,并且距离其他错误类别的模板距离相等。
为了观察标签平滑的这一特性,我们提出了一种新的可视化方案,该方案基于以下步骤:
选择三个类 找到跨越这三个类模板的平面的一个标准正交基 将这三个类中实例的倒数第二层激活投影到这个平面上。 这个可视化显示了激活是如何围绕模板聚集的,以及标签平滑是如何在示例和来自其他类的集群之间强制执行一个结构的。
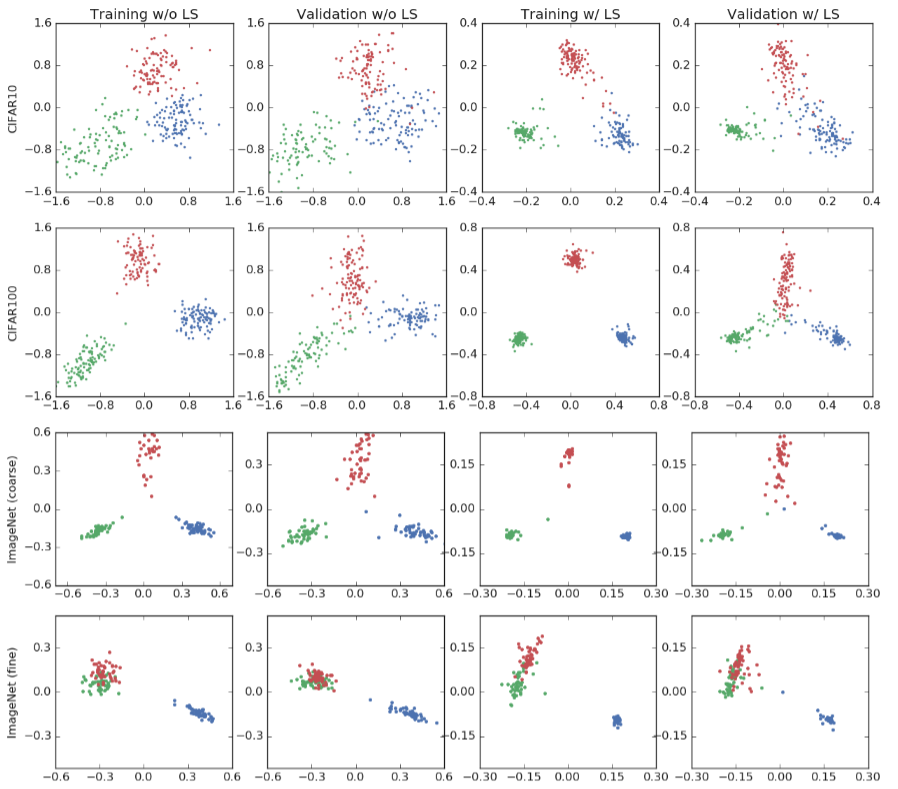
为了更好的展示 LS 给模型的倒数第二层输出x 带来的变化,作者选取了3个数据集,并在每个数据集中选择了一些类别,对这些类别中样本对应的x进行了可视化处理。在下图中,4行对应4个数据集&类别:
CIFAR-10数据集,飞机、车、鸟 CIFAR-100数据集,海狸、海豚、水獭 ImageNet数据集,某种鱼、狐獴、某种刀,这三个类别相差很大 ImageNet数据集,某种贵宾犬、另一种贵宾犬、某种鱼,其中前两个类别很相似 四列分别对应的是:训练集不加LS,验证集不加LS,训练集加LS,验证集加LS。
可以看到,LS 会让每个类别的cluster变得更加紧密。同时作者还附上了三个数据集上增加LS之后的效果变化,可以看出CIFAR-10和CIFAR-100两个数据集上都提升了ACC,而ImageNet数据集上ACC没有变化。
可视化倒数第二层的激活:AlexNet/ cifar10(第一行)、CIFAR100/ResNet-56(第二行)和ImageNet/ intercepte -v4(三个语义上不同的类(第三行)和两个语义上相似的类加上第三个类(第四行)。 可视化倒数第二层的激活:AlexNet/ cifar10(第一行)、CIFAR100/ResNet-56(第二行)和ImageNet/ intercepte -v4(三个语义上不同的类(第三行)和两个语义上相似的类加上第三个类(第四行)。 我们观察到这些预测被分散到定义明确但范围广泛的集群中。最后两列显示了用0.1的标签平滑因子训练的网络。我们观察到现在的聚类更加紧密 ,因为标签平滑鼓励训练集中的每个示例与其他类的所有模板的距离相等。因此,在观察投影时,在使用标签平滑训练时,集群组织在正三角形中,而在使用硬目标训练(没有标签平滑训练)时,正三角形结构不易识别。请注意,这些网络具有相似的准确性,尽管在性质上不同的激活集群。
在第二行,我们研究了不同的数据集/架构(CIFAR-100/ResNet-56)的激活几何结构。我们再次观察到“海狸”、“海豚”、“水獭”类的相同行为。与前面的例子相比,现在使用标签平滑训练的网络具有更好的准确性。 此外,我们观察了使用标签平滑和不使用标签平滑训练的网络之间投影的不同尺度。通过标签平滑,将两类的logit的差值限制在绝对值上,从而得到正确和错误的3类的期望软目标。然而,如果没有标签平滑,投影可以取更高的绝对值,这表示过度自信的预测。
最后,我们在Inception-v4/ImageNet实验中测试我们的可视化方案,并观察对语义相似的类进行标签平滑的效果,因为ImageNet有许多细粒度的类(例如不同品种的狗)。第三行表示语义上不同类(tench、meerkat和cleaver)的投影,其行为与之前的实验类似。第四行更有趣,因为我们选择了两个语义相似的类(toy poodle和miniature poodle),并在第三个语义不同的类(tench,蓝色)出现时观察投影。在硬目标中,语义相似的类以各向同性的方式聚在一起。相反,通过标签平滑,这些相似的类位于一个弧中。在这两种情况下,即使在训练集中,语义相似的类也很难分离,但标签平滑强制每个示例与所有剩余的类模板等距,这导致了相对于其他类的弧形行为。 我们还观察到,在没有标签平滑的训练中,“tench”聚类与“poodles”聚类之间存在连续的变化程度。我们还可以测量“贵宾犬在多大程度上是一种特殊的坦奇犬”。然而,当使用标签平滑训练时,这些信息实际上被删除了。 信息的删除在第4节中显示。最后,从图中可以看出,标签平滑对表示的影响与体系结构、数据集和准确性无关。
3 Implicit model calibration
通过人为软化目标,标签平滑可以防止网络变得过于自信。但是,它能通过使预测的可信度更准确地代表其准确性来改善模型的校准吗? 在本节中,我们试图回答这个问题。Guo等人的[15]研究表明,现代神经网络虽然比过去的神经网络有更好的校准性能,但校准效果较差,且过于自信。为了测量校准,作者计算了估计期望校准误差(ECE)。他们证明,一个简单的后处理步骤,温度缩放,可以减少ECE和校准网络。温度标度包括在应用softmax算子之前将对数乘以一个标量。在这里,我们展示了标签平滑也降低了ECE,并可以用于校准网络,而不需要温度缩放。
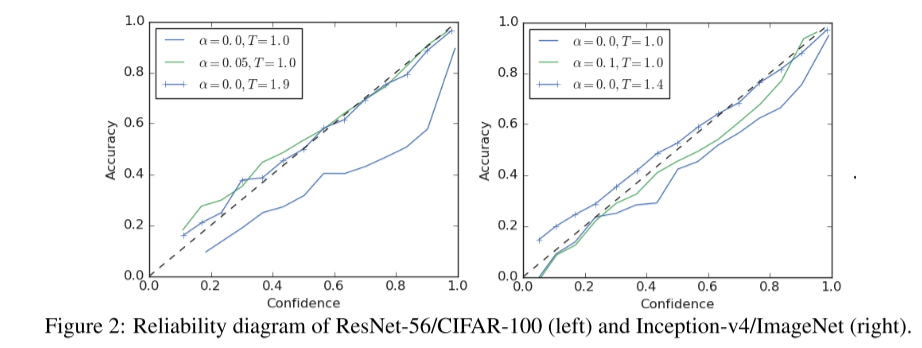
图片分类任务 :我们从研究图像分类模型的校准开始。图2(左)显示了在CIFAR-100上训练的ResNet-56的15 bin可靠性图。虚线表示完美的校准,输出的可能性(置信度)完美地预测了精度。在没有温度标度的情况下,用硬目标(蓝线,没有标记)训练的模型明显过于自信,因为预期的精度总是低于置信值。为了校准模型,可以将softmax温度后置(带叉的蓝线)调至1.9的温度。我们观察到,可靠性图的斜率现在更接近斜率1,模型得到了更好的校准。我们还表明,在校正方面,标签平滑也有类似的效果。通过训练α = 0.05(绿线)的同一模型,我们得到了一个与温度标度相似的校准模型。在表3中,我们观察了不同的标签平滑和温度标度如何影响ECE。这两种方法都可以将ECE降低到与用硬目标训练的未校准网络相似且较小的值。
我们还在ImageNet上进行了实验(图2右)。同样,用硬目标(没有标记的蓝色曲线)训练的网络过于自信,获得了0.071的高ECE。使用温度标度(T= 1.4), ECE降低到0.022(带叉的蓝色曲线)。虽然我们没有对α进行广泛的调整,但我们发现α = 0.1的标签平滑将ECE提高到0.035,与用硬目标训练的未缩放网络相比,得到了更好的校准。
下图中,α是LS的超参,T是Temprature scaling的超参。图的横轴是 confidence(也就是模型输出的 logits),纵轴是 ACC,理想情况是虚线。两个图分别表示了在两个图片分类数据集上的效果。可以看出在不加 TS 和 LS 的情况下,模型的 calibration 远差于理想情况,而增加了TS或者LS之后,模型的calibration都有提升。
根据上一节中显示的这些网络的倒数第二层可视化,这些结果有些令人惊讶。尽管试图将训练示例分解成小簇,但这些网络仍然可以进行归纳和校准。 看看图1中CIFAR100的标签平滑表示(第二行,最后两列),我们清楚地观察到这种行为。红色的聚类在训练集中非常紧凑,但在验证集中,它向中心扩散,代表每个预测的全范围的置信度。
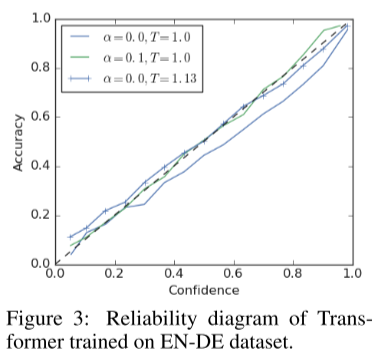
机器翻译: 我们还研究了使用Transformer架构对英语到德语翻译任务训练的模型的校准。这个设置之所以有趣,有两个原因。首先,Vaswani et al.[11]注意到α = 0.1的标签平滑提高了他们的最终模型的BLEU得分,尽管与用硬目标训练的模型相比(α = 0.0)会获得更糟糕的困惑。因此,我们在校准方面比较了这两种设置,以验证标签平滑也改善了该任务中的校准。其次,与图像分类相比,在图像分类中,校准不会直接影响我们所关心的度量(准确性),在语言翻译中,网络的软输出是对受校准影响的第二种算法(波束搜索)的输入。由于波束搜索近似于最大似然序列检测算法(Viterbi算法),我们可以直观地期望一个更好的校准模型有更好的性能,因为模型的置信度预测下一个令牌的准确性更好。
我们首先看看用硬目标(有或没有温度标度)训练的变压器网络和用标签平滑(α = 0.1)训练的网络的可靠性图(图3)。假设验证集上有正确的前缀,我们绘制下一个令牌预测的校准图。结果与之前在CIFAR-100和ImageNet上的实验结果一致,实际上,带有标签平滑的Transformer网络[11]比硬目标方案的校准效果更好。
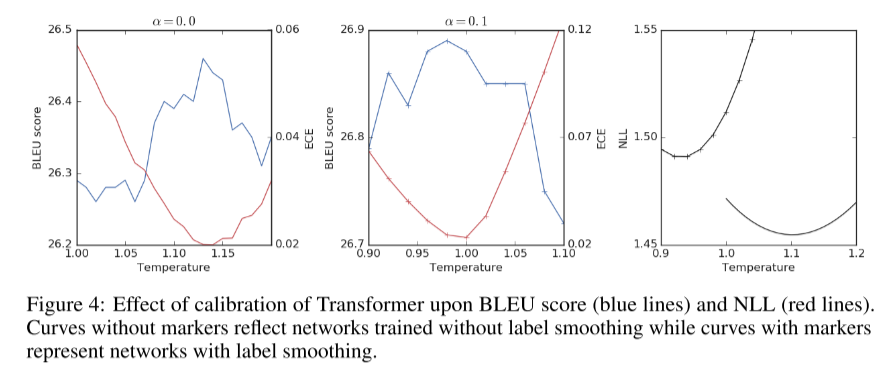
尽管标签平滑能更好地校准和获得更好的BLEU分数,但其负对数可能性(NLL)却比硬目标更差。此外,用硬目标进行温度变换不足以恢复用标签平滑获得的BLEU评分提高。 在图4中,我们使用温度标度对两个网络的标定进行人工改变,并分析对BLEU和NLL的影响。左边的面板显示了用硬目标训练的网络的结果。通过提高温度,我们既可以降低ECE(红色,右y轴),又可以略微提高BLEU分数(蓝色,左y轴),但BLEU分数的提高不足以与经过标签平滑训练的网络的BLEU分数相匹配(中间面板)。通过标签平滑训练的网络被“自动校准”,改变温度会降低校准和BLEU评分。最后,在右边的面板中,我们为两个网络绘制NLL,其中标记表示使用标签平滑的网络。用硬目标训练的模型在所有温度标度设置下均能获得较好的NLL。因此,在NLL较差的情况下,标签平滑提高了由BLEU评分衡量的翻译质量,而校准只能部分解释BLEU评分性能的差异。注意,在这个实验中,最低的ECE预测的最高BLEU分数略好于NLL。
右边的图可以得出的结论是,是在任何T下LS的NLL都没有变好(有叉叉的是LS的,没有叉的是hard label)。这里想说明的是,实际上LS在没有提升NLL的情况下,提升了BLEU。
4 Knowledge distillation
在本节中,我们研究使用标签平滑来训练教师网络如何影响将教师的知识提炼成学生网络的能力。我们发现,即使标签平滑提高了教师网络的准确性,接受标签平滑训练的教师与接受硬目标训练的教师相比,产生的学生网络质量较差。 在尝试在[16]中复制一个结果时,我们第一次注意到这种效果。对非卷积教师进行随机翻译的MNIST数字硬目标和辍学训练,测试误差为0.67%。通过使用蒸馏,这个教师可以用未翻译的数字来训练较窄的、非规则的学生,从而获得0.74%的测试误差。如果我们使用标签平滑而不是dropout,那么教师的训练速度会快得多,成绩也会稍微好一点(0.59%),但蒸馏会产生一个差得多的学生,测试误差为0.91%。当老师接受标签平滑训练时,蒸馏就出现了严重的问题。
在知识蒸馏中,我们将交叉熵项H(y, p)替换为加权和(1−β)H(y, p) + βH(pt(T), p(T)),其中pk(T)和pt k(T)分别是学生和教师用温度T标度后的输出。β控制两个任务之间的平衡:拟合硬目标和接近软化教师。温度可以被看作是夸大错误答案概率差异的一种方式。
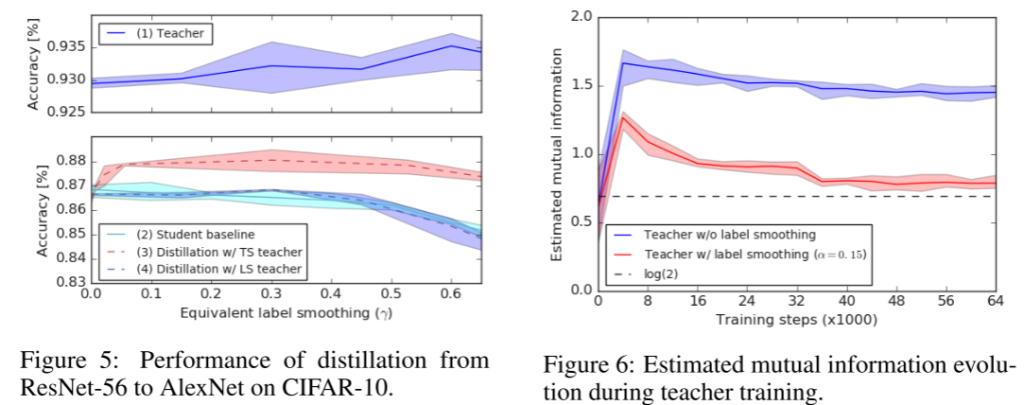
标签平滑和知识蒸馏都涉及到用软目标拟合模型。知识蒸馏只有在它比标签平滑训练学生提供额外收益时才有用,标签平滑训练更容易实现,因为它不需要训练教师网络。我们通过实验量化这个增益。为了演示这些想法,我们在CIFAR-10数据集上进行了一个实验。我们训练ResNet-56的老师然后我们提炼出AlexNet的学生。我们对四个结果感兴趣:
教师的准确性作为标签平滑因子的函数, 学生的基线精度,作为一个函数的标签平滑因子没有蒸馏, 学生经温度标度蒸馏后的准确性,以控制教师提供的目标(硬目标训练的教师)的平滑度 固定温度蒸馏后学生的准确度(T = 1.0,经过标签平滑训练的教师,以控制教师所提供目标的平滑度) 为了比较所有的解使用单一的平滑指数,我们定义了等效标签平滑因子γ,它对于场景1和场景2等于α。对于场景3和场景4,平滑指数为:
它计算教师在训练集上分配给错误示例的质量。由于训练精度接近完美,所以在所有蒸馏实验中,我们只考虑β = 1的情况,即目标为教师输出,忽略真实标签。
蒸馏实验结果如图5所示。我们首先比较未经蒸馏训练的教师网络(蓝色实心曲线,上)和学生网络(浅蓝色实心曲线,下)的性能。对于这种特殊的设置,增加α可以提高教师的准确性,使其达到α = 0.6的值,而标签平滑会略微降低学生网络的基线性能。
接下来,我们用不同的温度将受过硬目标训练的教师提取到学生身上,计算出每个温度对应的γ值(红色虚线曲线)。我们观察到,所有的蒸馏模型优于基线学生的标签平滑。 最后,我们用标签平滑α > 0方法对经过训练的教师进行信息提取,得到了更准确的信息(蓝色虚线曲线)。从图中可以看出,使用这些表现较好的教师并不比直接使用标签平滑来训练学生更好,有时甚至更差,因为在对教师进行标签平滑训练时,logit之间的相关信息会被“抹去”。
为了观察标签平滑是如何“擦除”包含在不同相似点中的信息的,我们回顾了图1中的可视化。请注意,我们对来自训练集的示例的可视化感兴趣,因为这些是用于蒸馏的示例。对于以硬目标(α = 0.0)训练的教师,我们观察到样本分布在广泛的集群中,这意味着同一个班级的不同样本与其他班级的相似点可能非常不同。对于受过标签平滑训练的教师,我们观察到相反的行为。标签平滑鼓励示例位于紧密的等分簇中,因此一个类的每个示例与其他类的示例具有非常相似的近似性。因此,一个准确率更高的老师,并不一定是一个精进得更好的老师。
一种直接量化信息擦除的方法是计算输入和logit之间的互信息 。
和
其中:
L为用于计算经验均值的蒙特卡罗样本数,N为用于互信息估计的训练样本数。这里的互信息在0和log(N)之间。
图6显示了训练示例的一个子集(两个类的N = 600)之间的估计互信息和两个类对应的logit的差值。初始化后,互信息很小,但随着网络的训练,它先是迅速增加,然后慢慢减少,特别是对于经过标签平滑训练的网络。这一结果证实了上一节的直觉。当表示崩溃为小的点簇时,许多可以帮助区分示例的信息就丢失了。这导致接受标签平滑训练的教师估计互信息较低,蒸馏效果较差。对于训练的后期阶段,互信息略高于log(2),对应于所有训练示例崩溃为两个独立聚类的极端情况。在这种情况下,除了表示示例属于哪个类的一位外,所有的输入信息都被丢弃,这导致教师的日志中没有与标签中的信息相比的额外信息。
5 Related work
Pereyra等人的[17]表明,标签平滑在许多任务中提供了一致的收益。这项工作还提出了一种基于惩罚低熵预测的新正则化方法,作者将其称为“置信度惩罚”。他们表明,如果均匀分布和模型输出之间KL散度的顺序颠倒,则标签平滑相当于置信度惩罚。他们还建议使用非均匀分布,从而得到ungram标签平滑(见表1),当输出标签的分布不平衡时,这是有利的。标签平滑也涉及到扰乱标签[18],可以看作是标签dropout,而标签平滑是标签dropout的边缘版本。
现代神经网络[15]的定标已被广泛用于图像分类,但序列模型的定标直到最近才被研究。Ott等人的[19]研究了机器翻译模型的序列水平校准,并得出结论,它们的校准非常好。Kumar和Sarawagi[20]研究了语言翻译中下一个令牌预测的校准。他们发现,参数化模型可以改善最先进模型的校准,从而导致BLEU分数的小幅增加。然而,没有一篇文章研究训练过程中的标签平滑与校准之间的关系。对于语音识别,Chorowski和Jaitly[10]研究了软码温度和标签平滑对解码精度的影响。结果表明,温度标度和标度平滑均能提高波束搜索后的错误率(标度平滑效果最好),但没有描述标度和标度/温度标度之间的关系。
虽然我们不知道之前的任何工作都显示了标签平滑在蒸馏后的不利影响,Kornblith等人[21]之前证明了标签平滑降低了迁移学习的准确性,而迁移学习同样依赖于在网络的最后一层是否存在非类相关信息。Chelombiev et al.[22]提出了一种改进的基于binning的互信息估计器,并显示了softmax层表示的压缩与泛化之间的相关性,这可以解释为什么使用标签平滑训练的网络具有如此好的泛化效果。这与信息瓶颈理论有关[23,24,25],该理论从压缩的角度解释了泛化。
6 Conclusion and future work
许多最先进的模型都是用标签平滑来训练的,但是这种技术提供的归纳偏差还没有被很好地理解。在这项工作中,我们总结并解释了在使用标签平滑训练深度神经网络时观察到的几种行为。我们关注的是标签平滑如何鼓励倒数第二层的表示在紧密的等距离的簇中分组。由于我们提出了一种新的可视化方案,这种涌现性可以在低维度下可视化。尽管标签平滑对泛化和校准有积极的影响,但它会影响蒸馏。 我们从删除信息的角度来解释这种效应。使用标签平滑,鼓励模型将每个不正确的类视为等可能的。对于硬目标,在以后的表示中强制的结构更少,使得预测的类和/或示例之间有更多的logit变化。这可以通过估计输入示例和输出logit之间的互信息来量化,正如我们所展示的,标签平滑减少了互信息。这一发现提出了一个新的研究方向,即标签平滑与信息瓶颈原理之间的关系,对压缩、泛化和信息传输具有启示意义。最后,我们对标签平滑如何隐式校准模型的预测进行了广泛的实验。这对模型的可解释性有很大的影响,但正如我们所展示的,这对依赖于校准可能性的下游任务(如波束搜索)也至关重要。









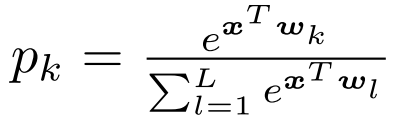
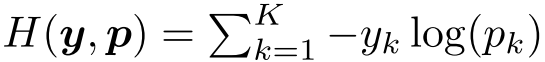
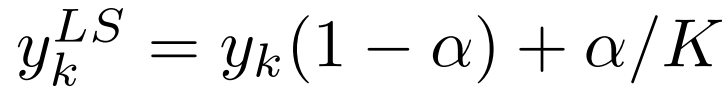
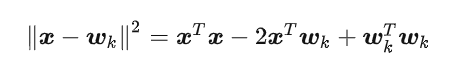


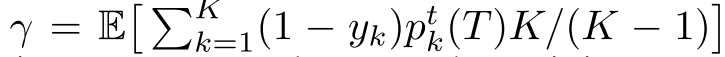
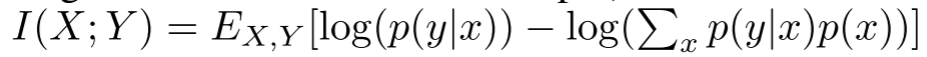
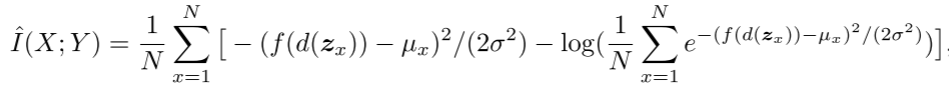




Comments | NOTHING