最近,随着深度学习的成功,在各个领域都取得了出色的突破(Ronneberger et al., 2015;Devlin et al., 2018;任等,2015)。然而,最先进的深度神经网络总是消耗大量的计算量和内存,这限制了它们在自动驾驶汽车和手机等边缘设备上的部署。为了解决这个问题,提出了大量的技术,包括剪枝(Han et al., 2016;Zhang et al., 2018;Liu et al., 2018;Frankle & Carbin, 2018),量化(Nagel等人,2019;Zhou等人,2017),紧凑型模型设计(Sandler等人,2018;Howard等人,2019年;Ma et al., 2018;Iandola等人,2016)和知识蒸馏(Hinton等人,2014;Buciluˇet al., 2006)。知识蒸馏又称师生学习,其目的是将过度参数化的教师的知识传递给轻量级的学生。由于学生接受的训练是模仿老师的逻辑或特征,学生可以从老师那里继承黑暗知识,因此往往获得更高的准确性。由于其简单、有效的特点,知识蒸馏已成为模型压缩和提高模型精度的常用方法。
目标检测作为计算机视觉领域最关键的挑战之一,迫切需要精确和高效的模型。不幸的是,现有的计算机视觉知识蒸馏方法大多是为图像分类而设计的,通常会导致对目标检测的微小改进(Li et al., 2017)。本文将知识蒸馏在目标检测中的失败归结为以下两个问题,分别待后续解决。
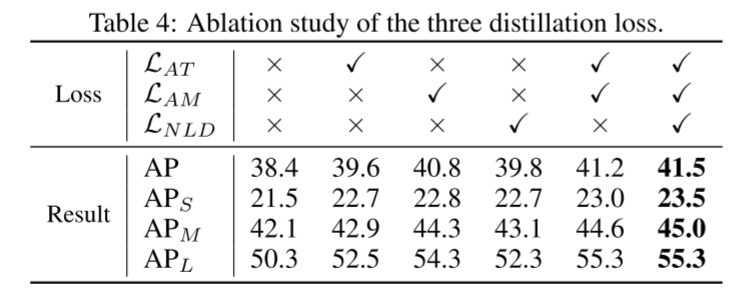
前景与背景的不平衡。在待检测的图像中,背景像素往往比前景对象的像素更令人难以抗拒。然而,在之前的知识提炼中,学生总是被训练以相同的优先级模仿所有像素的特征。因此,学生将大部分注意力集中在学习背景像素特征上,抑制了学生对前景物体特征的学习。由于前景像素在检测中起着至关重要的作用,这种不平衡严重影响了知识蒸馏的性能。为了克服这个障碍,我们提出了注意力引导蒸馏,它只蒸馏关键的前景像素。由于注意图能够反映重要像素点的位置(Zhou et al., 2016),我们采用注意图作为知识蒸馏的掩模。将关注值较高的像素作为前景对象的一个像素,然后由优先级较高的学生模型进行学习。与之前的二值掩码方法(Wang et al., 2019)相比,我们的方法中由注意图生成的掩码粒度更细,不需要额外的监督。与以往基于注意力的精馏方法(Zagoruyko & Komodakis, 2017)相比,我们的方法不仅将注意力地图作为待提取的信息,还将其作为掩模信号进行特征提取。
缺乏对关系信息的蒸馏。在物体检测中,不同物体之间的关系是公认的有价值的信息。近年来,许多研究人员成功地提高了探测器的性能,使探测器能够捕获和利用这些关系,如非局部模块(Wang et al., 2018)和关系网络(Hu et al., 2018)。然而,现有的目标检测知识提取方法只是提取单个像素的信息,而忽略了不同像素之间的关系。为了解决这一问题,我们提出了非局部提取方法,该方法利用非局部模块捕获学生和教师之间的关系信息,然后将这些信息从教师提取到学生。
知识蒸馏作为一种有效的模型压缩和模型精度提升方法,被广泛应用于各个领域和任务中,包括图像分类,目标检测、语义分割、人脸识别、预训练语言模型、多出口网络训练(Zhang et al., 2019b;a)、模型鲁棒性(Zhang et al., 2020b)等。Hinton等人(2014)首先提出了知识蒸馏的概念,即训练学生模拟教师的软max层后的结果。然后,在教师特征(Romero et al., 2015)或变异中提出了丰富的知识转移方法,如Attention, FSP (Yim et al., 2017),互信息(Ahn et al., 2019),积极特征(Heo et al., 2019),批次样品的关系。
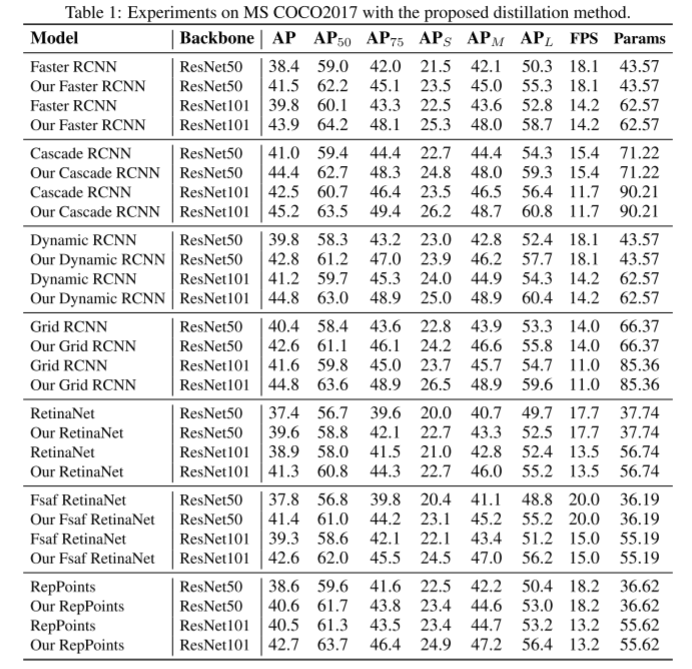
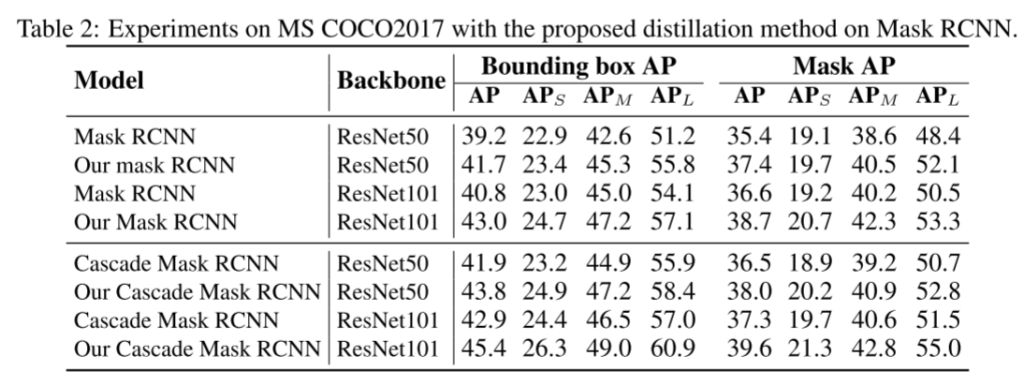
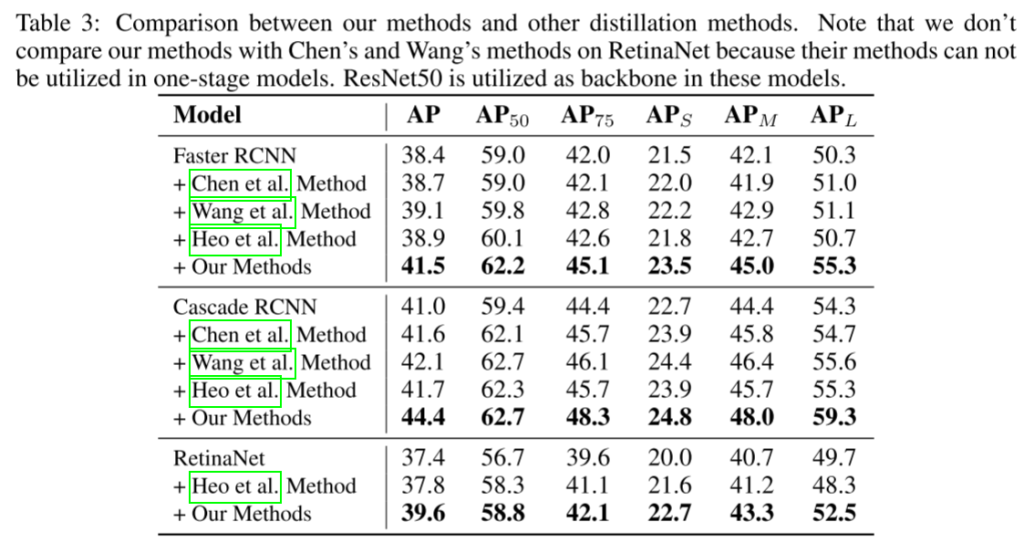
提高目标检测的性能是近年来知识蒸馏研究的一个热点。Chen et al.(2017)设计了第一个基于对象检测的知识蒸馏方法,包括主链、分类头和回归头的蒸馏损失。然后,许多研究者发现前景物体与背景的不平衡是检测蒸馏中的一个关键问题。Li等人(2017)没有提取骨干网络的全部特征,而是只对RPN采样的特征应用L2蒸馏损失。Bajestani和Yang(2020)提出了时间知识蒸馏,它引入了一个超参数来平衡前景和背景像素之间的蒸馏损失。Wang et al.(2019)提出了细粒度特征模仿,它只提取目标锚点附近的特征。然而,这些作品虽然尝试只提取前景对象的像素点,却总是在groundtruth、anchor、bounding box的注释上做出回应,无法转移到不同种类的检测器和任务上。
在该方法中,利用注意机制找到前景目标的像素点,该像素点很容易从特征中生成。因此,它可以直接应用于各种探测器上,无需任何修改。如图3所示,之前基于掩码的检测精化方法(Wang et al., 2019)与我们的注意力引导精化方法的区别如下:
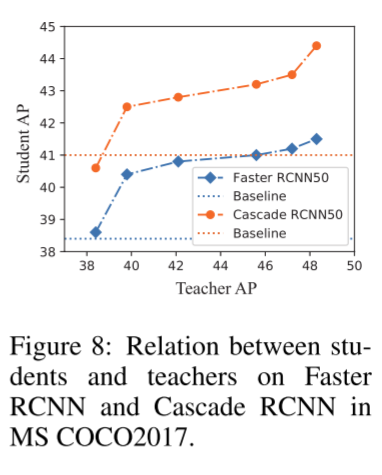
5.2 RELATION BETWEEN STUDENT DETECTORS AND TEACHER DETECTORS.
有足够的研究关注学生和教师之间的关系。Mirzadeh et al.(2019)和Cho & Hariharan(2019)表明准确性较高的教师可能不是知识提炼的更好的教师,有时准确性过高的教师可能会损害学生的表现。此外,Mobahi et al.(2020)和Yuan et al.(2019)表明,同样的模型,甚至精度低于学生模型的模型,都可以作为教师模型进行知识蒸馏。但是他们的实验都是在图像分类上进行的。在本节中,我们研究这些观察是否仍然适用于目标检测的任务。如图8所示,我们在不同AP教师模型的Faster RCNN (ResNet50 backbone)和Cascade RCNN (ResNet50 backbone)学生上进行实验,观察到:








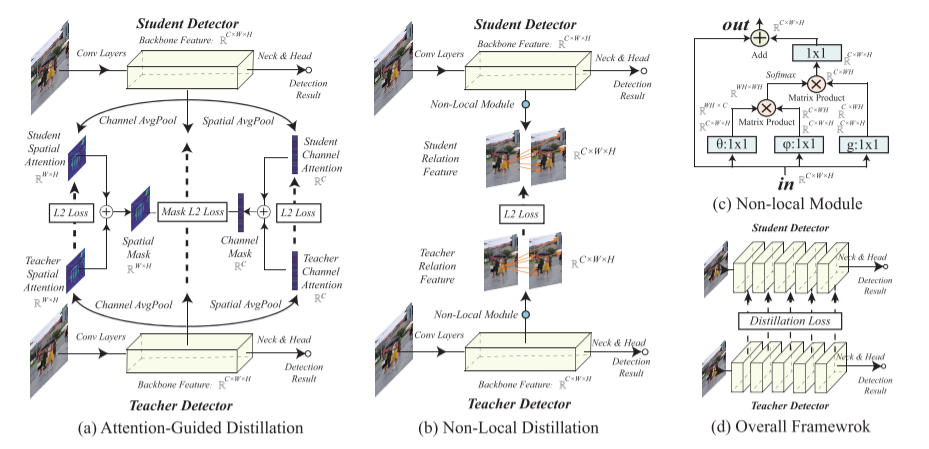

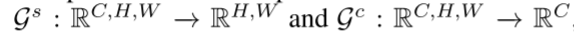
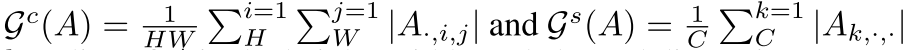


 由注意转移损失
由注意转移损失 和注意掩模损失
和注意掩模损失 两部分组成。利用
两部分组成。利用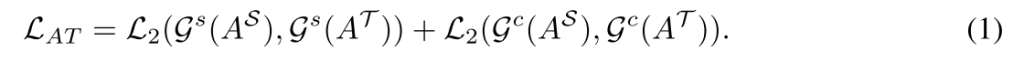
 和
和 所掩盖的
所掩盖的 规范缺失,
规范缺失,
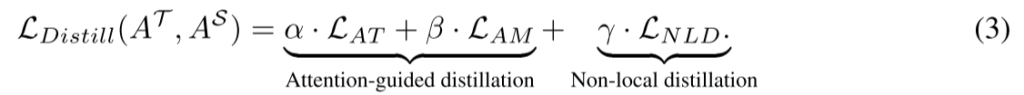




Comments | NOTHING