MoveNet和MediaPipe都是Google的开源项目,用于人体姿态估计和媒体处理。
MoveNet是一个为实时人体姿态估计设计的轻量级机器学习模型。它能够检测图像或视频中人的关键点,如脸部、手部、脚部等,并估计出其身体姿态。MoveNet有两种版本,一种是Lightning版,一种是Thunder版。这两种版本都可以检测到17个主要的身体关键点。它被设计为能够在各种设备上运行,包括移动设备和边缘设备,以支持各种应用,如健康健身、游戏、AR等。MoveNet提供了多种版本的模型,包括Lightning(针对速度优化)和Thunder(针对准确性优化)。
MediaPipe是一个跨平台的框架,用于构建和运行用于机器学习的多媒体处理管道。它提供了各种预先训练的模型和工具,可以用来处理音频、视频、图像和传感器数据。MediaPipe可用于构建各种应用,包括人脸检测、手势识别、物体检测、人体姿态估计等。MoveNet有两种版本,一种是Lightning版,一种是Thunder版。这两种版本都可以检测到17个主要的身体关键点。MediaPipe支持在各种平台和设备上运行,包括Android、iOS、Web和Desktop。
两者都被广泛应用于许多应用程序,包括健身应用、游戏、视频会议和许多其他与机器学习、计算机视觉和人工智能相关的应用。
什么是人体姿态估计
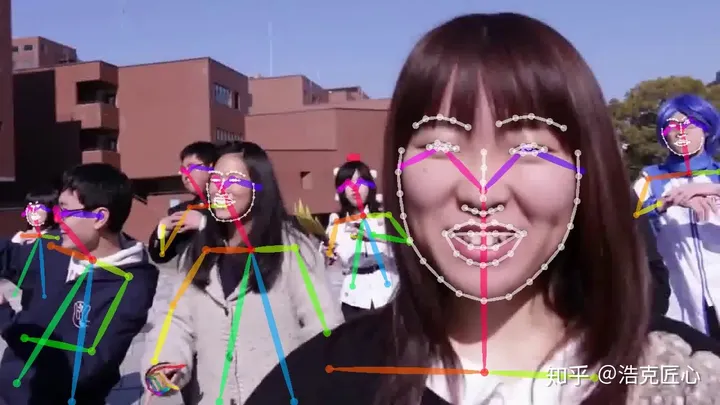
人体姿态估计,pose estimation,就是通过将图片中已检测到的人体关键点正确的联系起来,从而估计人体姿态。
人体关键点通常对应人体上有一定自由度的关节,比如颈、肩、肘、腕、腰、膝、踝等,如下图。
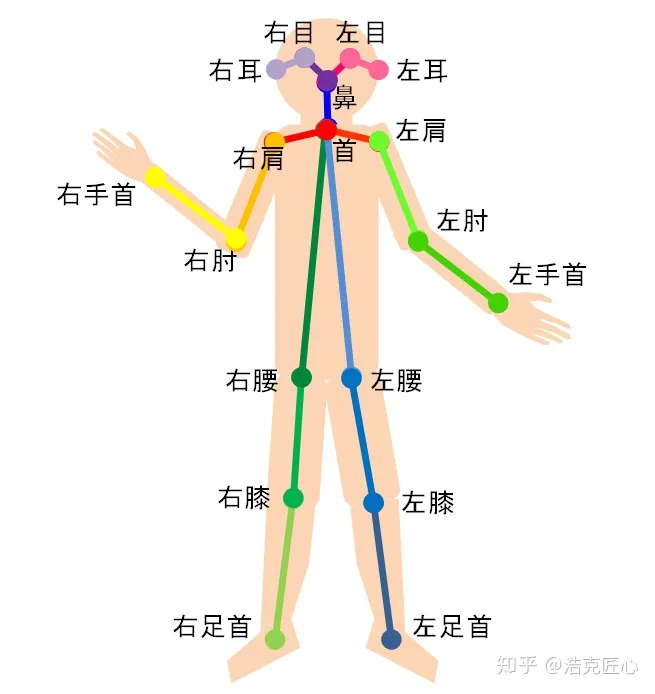
通过对人体关键点在三维空间相对位置的计算,来估计人体当前的姿态。
进一步,增加时间序列,看一段时间范围内人体关键点的位置变化,可以更加准确的检测姿态,估计目标未来时刻姿态,以及做更抽象的人体行为分析,比如判断一个人是否在打电话等等。
姿态检测的挑战:
- 每张图片中包含的人的数量是未知的。
- 人与人之间的相互作用是非常复杂的,比如接触、遮挡等,这使得联合各个肢体,即确定一个人有哪些部分变得困难。
- 图像中人越多,计算复杂度越大(计算量与人的数量正相关),这使得real time变得困难。
单人姿态评估方法
对于单人姿势估计,传统的机器学习方法主要采用线性判别函数,往往难以在大量复杂相似的样本上取得好的检测效果。而深度学习凭借强大的自主学习能力和高度的非线性映射特性,可以得到语义信息更为丰富的特征,能够获得不同感受野下多尺度多类型的人体关节点特征向量和每个特征的全部上下文(contextual)信息,摆脱对部件模型结构设计的依赖。
基于卷积神经网络的姿态估计
基于生成对抗网络的姿态估计
基于组合模型的姿态估计
多人姿态评估方法
多人姿态估计一般有两种方法:一种是自上而下的方法[35-37],即首先使用人体检测器检测出图像中的所有单个人体,然后对检测出的单个人体分别进行关节点检测,进而估计出每个人的姿态;另外一种是自下而上的方法[38-4],即先检测出图像中所有人体关节点,根据人体结构先验对检测出的关节点进行重新组合,使得人体与自身关节点正确匹配,进而实现对每个人的姿态估计。通常情况下,自上而下方法只需对图像中被检测出的单个人体进行姿态估计,不需要区分身体部件和解决关节点在全图中的归属问题,相比较自下而上的方法,更加容易实现。但是,正因为自上而下方法的这一特性,当图像中人体出现相互遮挡时,更容易出现重复检测和错误估计等问题
自上而下的评估方法
自下而上的评估方法
人体姿态检测数据集
1. HiEve数据集
数据集链接:Human in Events
数据集图片:
•在以人为中心的分析和了解复杂事件中,鼓励并加快新技术的开发。
•在“复杂事件中的大型以人为中心的视觉分析”方面培养新的思想和方向。
数据集内容:HiEve数据集,主要包括在各种人群和复杂事件(包括地铁上下车,碰撞,战斗
和地震逃生)中,以人为中心的非常具有挑战性和现实性的任务。
数据集数量:HiEve数据集包括当前最大的姿势数(> 1M),最大的复杂事件动作标签的数量(> 56k),并且是具有最长期限的轨迹的最大数量之一(平均轨迹长度> 480)。
数据集功能:人体检测、姿态识别、目标追踪、动作识别
2. MPII Human Pose数据集
数据集链接:MPII Human Pose Database (mpg.de)
数据集图片:

数据集内容:MPII Human Pose数据集,是用于评估人体姿势识别的数据集。
数据集涵盖了410种人类活动,并且每个图像都带有活动标签。每个图像都是从YouTube视频中提取的,并提供了之前和之后的未注释帧。
此外,对于测试集,我们标注了丰富的注释,包括身体部位遮挡以及3D躯干和头部方向。
数据集数量:该数据集包含约 25K图像,其中对超过4万名人体进行关节标注。
数据集功能:姿态识别
3. CrowdPose数据集
数据集链接:GitHub - Jeff-sjtu/CrowdPose: CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark, CVPR 2019, Oral
数据集图片:

数据集内容:CrowdPose数据集是一个用于拥挤场景姿势估计的新基准数据集,可用于拥挤场景下姿势估计问题。
数据集功能:姿态识别
4. Human3.6M
数据集图片:

数据集内容:Human3.6M数据集是一个3D人体姿态识别的数据集,通过4个经过校准的摄像机拍摄获得,对于3D人体的24个部位位置和关节角度都有标注。
数据集数量:Human3.6M数据集包含360万个3D人体姿势图像,11名专业演员(男6名,女5名),17个场景(讨论,吸烟,拍照,通电话...)。
数据集功能:姿态识别、3维重建
下载链接:点击查看
5. PedX数据集
数据集图片:
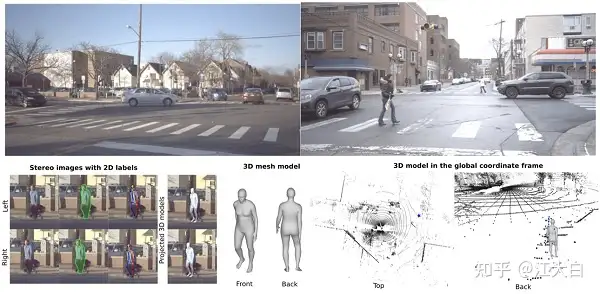
数据集内容:PedX 数据集是一个在复杂的城市交叉路口,对于行人进行采集的大规模多模式数据集。
该数据集提供高分辨率的立体图像,和具有手动2D和自动3D注释的LiDAR数据。此外,数据是使用两对立体相机和四个Velodyne LiDAR传感器进行的采集。
数据集功能:人体分割、姿态识别、人体检测
下载链接:点击查看
6. SURREAL数据集
数据集图片:

数据集内容:SURREAL数据集是一个大规模人造姿态识别数据集,对于RGB视频,对多种状态进行标注:深度信息,身体部位,光流,2D / 3D姿势等。这些图像是在形状,纹理,视点和姿势有很大变化的情况下,对人物的真实渲染。
数据集数量:数据集包含600万帧合成人体数据
数据集功能:姿态识别、人体分割
下载链接:点击查看
7. Mo2Cap2数据集
数据集图片:

数据集内容:硬件设置的移动性,在各种无限制的日常活动中,对3D人体姿势估计的稳定性会有影响。
因此,在Mo2Cap2数据集中,将头部的棒球帽,安装上一个鱼眼镜头类型的,高质量姿势估计设备。
除了新颖的硬件设置,该数据集主要贡献是:
(1)大型的自顶向下的鱼眼图像地面,实况训练数据集;
(2)一种新颖的3D姿态估计方法,该方法考虑了以自我为中心的独特属性。与现有算法基准相比,可以实现了更低的3D关节误差以及更好的2D覆盖。
数据集功能:姿态估计
下载链接:点击查看
8. DensePose数据集
数据集图片:

数据集内容:DensePose数据集是户外的密集人体姿势估计数据集,目的在于建立从2D图像到人体表面的多关键点密集对应关系。标注过程主要分为两个阶段:
第一阶段:标注人员会标注出身体部位,可见的对应区域。当然对于后面的身体部位,标注人员会进行估算标注。
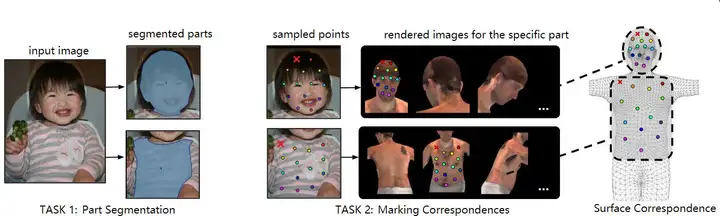
第二阶段中:使用一组大致等距的关键点,对每个零件区域进行采样,并要求标注人员将这些点与表面相对应,从而得到最终的标注信息。
数据集数量:DensePose数据集,对5万个人进行了标注,超过500万个标注信息。
数据集功能:姿态识别、人体分割
下载链接:点击查看
9. PoseTrack 数据集
数据集图片:


数据集内容:PoseTrack 数据集是用于人体姿势估计和视频中的关节跟踪的大型数据集,主要应用于两种挑战:“多人姿势估计”和“多人姿势跟踪”。
数据集数量:数据集中包含1356个视频序列,46000张标注的视频帧,276000个人体姿势标注信息。
数据集功能:姿态估计、姿态跟踪
下载链接:点击查看
目前的一些框架
OpenPose
描述:OpenPose是基于卷积神经网络和监督学习并以caffe为框架写成的开源库,可以实现人的面部表情、躯干和四肢甚至手指的跟踪,不仅适用于单人也适用于多人,同时具有较好的鲁棒性。可以称是世界上第一个基于深度学习的实时多人二维与三维姿态估计,是人机交互上的一个里程碑,为机器理解人提供了一个高质量的信息维度。
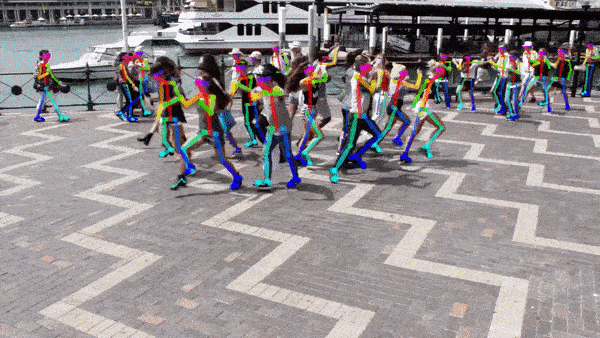
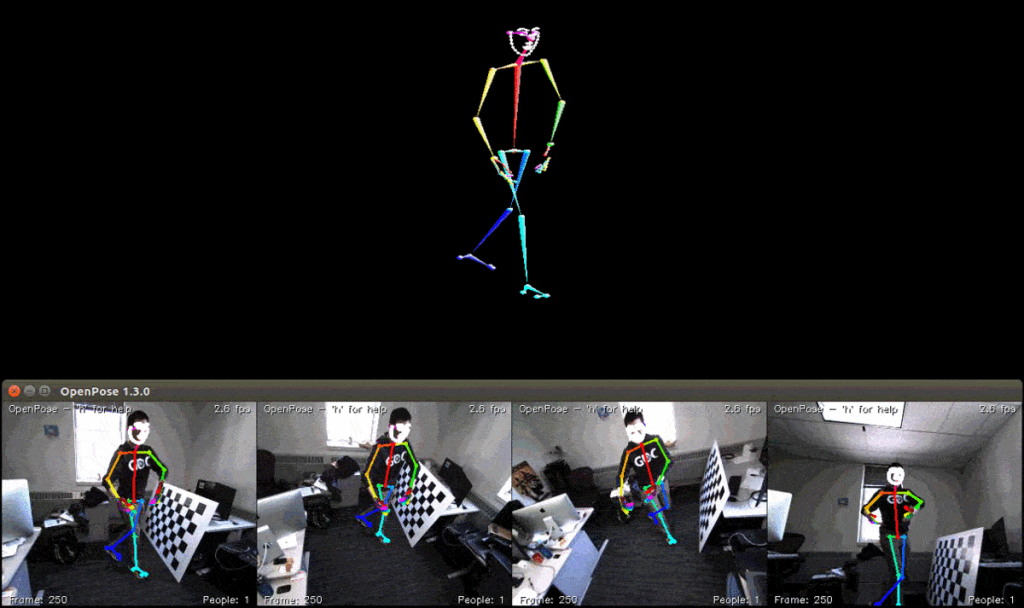
主要功能:
- 2D实时多人关键点检测:
- 15、18 或 25 个关键点的身体/脚关键点估计,包括 6 英尺的关键点。运行时对检测到的人数不变。
- 2x21 关键点手关键点估计。运行时间取决于检测到的人数。请参阅 OpenPose 训练,了解运行时固定替代方案。
- 70 个关键点人脸关键点估计。运行时间取决于检测到的人数。请参阅 OpenPose 训练,了解运行时固定替代方案。
- 3D 实时单人关键点检测:
- 来自多个单一视图的 3D 三角测量。
- 处理的Flir热像仪的同步。
- 与FLIR/点灰热像仪兼容。
适用场景:多人,2D、3D姿态检测
项目链接:https://github.com/CMU-Perceptual-Computing-Lab/openpose
理论基础:其理论基础来自Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields ,是CVPR 2017的一篇论文,作者是来自CMU感知计算实验室的曹哲


主要流程:
- 输入一幅图像,经过卷积网络提取特征,得到一组特征图,然后分成两个岔路,分别使用 CNN网络提取Part Confidence Maps 和 Part Affinity Fields;
- 得到这两个信息后,我们使用图论中的 Bipartite Matching(偶匹配) 求出Part Association,将同一个人的关节点连接起来,由于PAF自身的矢量性,使得生成的偶匹配很正确,最终合并为一个人的整体骨架;
- 最后基于PAFs求Multi-Person Parsing—>把Multi-person parsing问题转换成graphs问题—>Hungarian Algorithm(匈牙利算法)
(匈牙利算法是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。)
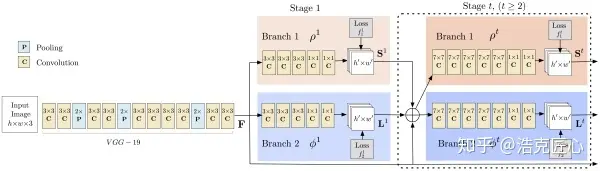
亮点1:PAF-Part Affinity Fields(本paper的核心贡献):
人体姿态检测,通常是top-down的思路,也就是先做行人检测,然后把每一个人分割出来,最后基于每一个独立个体,找出各自的手手脚脚(人体关键点)。这个办法有两个问题:
1.结果严重依赖第一步行人检测器的结果,如果人都没找到,就无从进行找手手脚脚这一步了。
2.计算时间和人数正相关,人越多越耗费时间。
OpenPose 使用了另一种思路,即bottom-up,先找出图中所有的手手脚脚,再用匹配的方法拼装成一个个人体骨架。这种办法有一个缺陷,就是没办法利用全局上下文的信息。
为了克服这个问题,本文想出了一个办法,就是PAF(Part Affinity Fields), 部分区域亲和。它负责在图像域编码着四肢位置和方向的2D矢量。同时,使用CMP(Part Detection Confidence Maps)标记每一个关键点的置信度(就是常说的“热图”)。通过两个分支,联合学习关键点位置和他们之间的联系。
同时推断这些自下而上的检测和关联的方式,利用贪婪分析算法(Greedy parsing Algorithm),能够对全局上下文进行足够的编码,获得高质量的结果,而只是消耗了一小部分计算成本。并行情况下基本达到实时,且耗时与图片中的人数无强关联。

亮点2: 高鲁棒性
这是CMU的研究成果。很多人好奇,为啥CMU的模型鲁棒性好,精度高?我觉得这主要归功于数据集规模大,质量好。
下图是CMU家的数据采集设备,一个封闭的大球,可以做到任意角度的人体数据采集。大球上面镶嵌了480 VGA cameras+31 HD cameras+10 Kinect Ⅱ Sensors+5 DLP Projectors. 并且,全部实现了硬件同步。
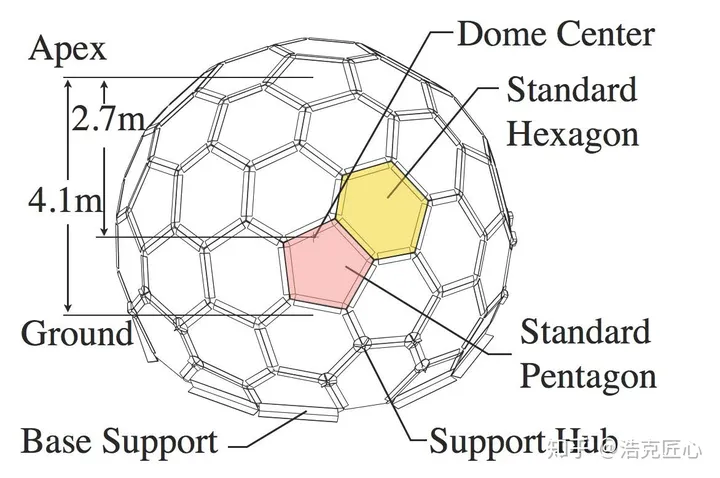
亮点3:终于将人体、人手、人脸的landmarks三元归一
以前,人体骨骼关节点是行为分析动作识别的人做,人脸landmark提取是人脸识别或者美颜算法开发团队做,手部关节点是手势识别人机交互团队在做,属于不同的细分方向。
CMU的团队,因为前期的人体骨骼关节点识别取得了不错的成果,有了更大的目标(野心),于是把人脸人手都整合了进来,做成了一个统一的graph,效果也还可以。face alignment和pose alignment串起来了,而且根据人体头部的刚体属性及四肢的非刚体特性设计了一套基于caffe的点估计与扩散模型,并建立树状决策加速,据此再加之3D背景分割技术。
当然,如果野心再大一点点,做一个结合了表情识别和手势识别的人体行为识别方案就更了不起了,比如人在打架的时候,脸部表情通常是紧绷或者愤怒的,手部通常会攥成拳头,这样,整合脸和手的识别结果,都整体复杂行为的分析和预测会有帮助。
多人70关键点人脸估计:
有什么短板?
耗显存
计算量本来就很大,为了达到实时的目的,使用了高并行的策略。基于cuda加速,所以非常吃显存,基本劝退显存低于4G的机器了(GTX 980ti+)。
时间分析(仅作参考):
<基于GTX-1080 GPU>
原始图像尺寸是1080×1920, 为了适应GPU memory,resize成了 368×654;
包含是19个人的视频检测是8.8 fps;
对于9个人, parsing耗时0.58 ms, CNN耗时99.6 ms。
特殊场景下检测效果差
比如人体姿势比较诡异的时候,如下图(曾经对这个场景产生过心理阴影)

非直立向上朝向的人

其他情况,诸如图像分辨率低、运动模糊、低亮度、检测目标密集、遮挡严重、不完整目标等,效果都不是很理想。但是,这是全天下图像检测算法都会犯的错。
- AlphaPose
- 描述:AlphaPose是一个在速度和准确性方面高效的多人姿态估计框架。
- 适用场景:多人,2D姿态检测
- 项目链接
- HRNet (High-Resolution Network)
- 描述:传统的卷积网络在多尺度处理上有限,而HRNet保持了高分辨率的特征在整个网络中,特别适合于姿态估计。
- 适用场景:多人,2D姿态检测
- 项目链接
- Simple Baselines for Human Pose Estimation and Tracking
- 描述:通过一些简化但有效的技巧来提高性能,主要是用于姿态估计和跟踪。
- 适用场景:多人,2D姿态检测
- 项目链接
- 3D human pose estimation
- 描述:与2D姿态检测不同,3D姿态估计旨在从2D图像中恢复3D姿态信息。有很多不同的研究和方法致力于此问题,如VideoPose3D和HMR。
- 适用场景:单人或多人,3D姿态检测
- 一些研究工作和代码库包括VideoPose3D和HMR。
- PoseNet
- 描述:用于姿势估计的轻量级模型,尤其是在移动设备上。
- 适用场景:单人,2D姿态检测
- 项目链接
- DeepPose
- 描述:是早期的深度学习方法之一,采用深度卷积神经网络。
- 适用场景:单人,2D姿态检测
- PoseNet
- 描述:由Google开发,特别为移动设备和前端应用进行了优化。
- 项目链接
- MobileNetV2+Deconv
- 描述:基于MobileNetV2的轻量级后处理,其结构被简化以进行姿态估计。
- 可以参考论文来获取更多的技术细节。
- MobilePose
- 描述:专为移动设备设计,其结构简化且有效。
- 项目链接
- LiteHRNet
- 描述:继承了HRNet的优点,但经过了优化和调整以减少计算量。
- 项目链接
- EfficientPose
- 描述:基于EfficientNet,这个模型有几种版本,从小型到大型,其中小型版本特别轻量。
- 项目链接
- PRNet (Pose Residual Network)
- 描述:旨在通过深度残差网络提高计算效率和精度。
- 可以查找相关文献来深入了解。
进展思路
方法技术指标以及比对分析
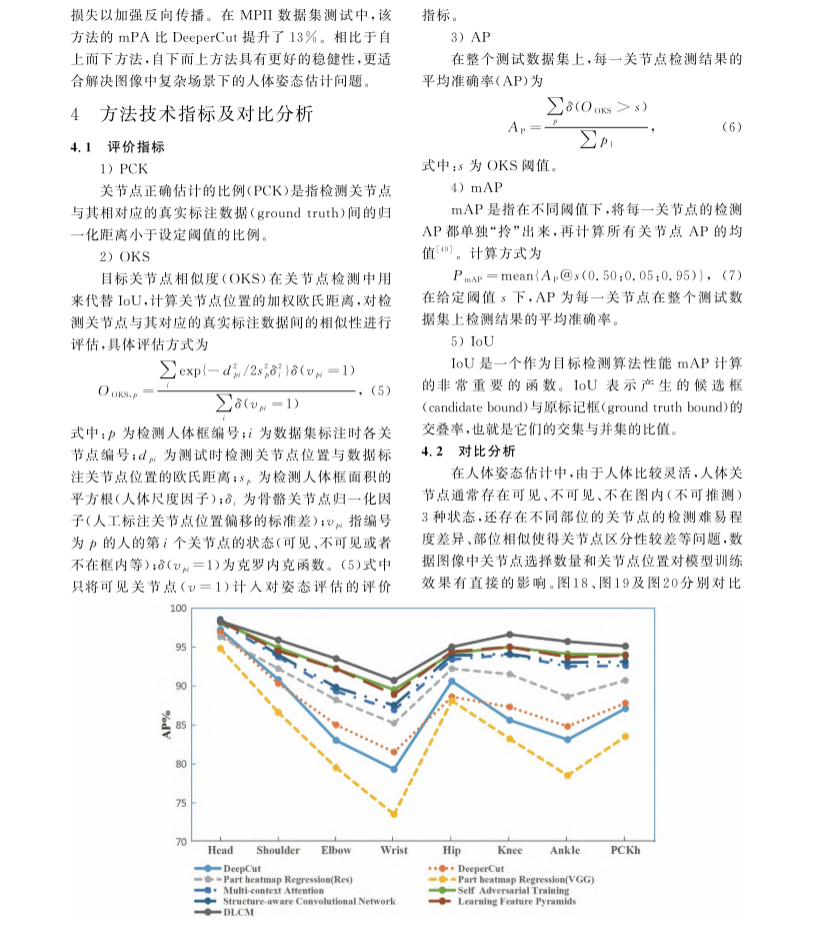
评价指标











Comments | NOTHING