







参考资料
轻量级姿态估计技巧总结(2023.3.22更新) - 知乎 (zhihu.com)
代码实践
1. 轻量姿态估计模型设计一
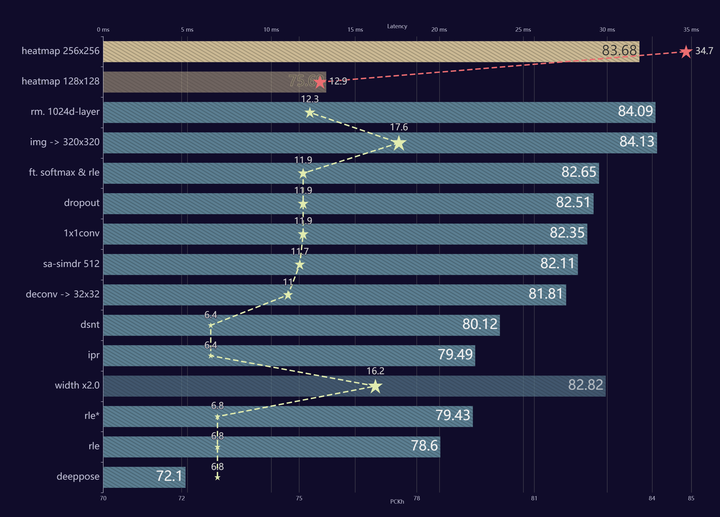
在 MPII 上设计了一个能用 CPU 跑到 100FPS 的轻量模型,亲手实现将 regression 方法优化到精度超越 heatmap 方法。
2. 轻量姿态估计模型设计二
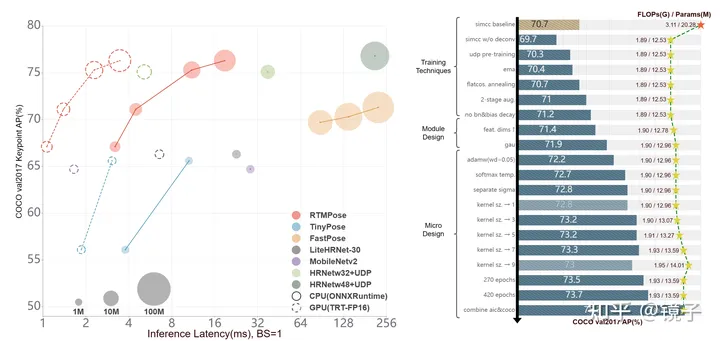
数据处理&增强篇
1. Augmentation by Information Dropping(AID)
地址:2020 COCO Keypoint Challenge 冠军之路 - 知乎 (zhihu.com)
这是COCO2020 冠军团队的论文之一。作者认为在姿态估计任务中,模型会使用两种信息:外观信息和约束信息。外观信息是定位关键点的基础,而约束信息则在定位困难关键点时具有重要的指导意义。约束信息包括人体关键点之间固有的相互约束关系(如人体关节的活动度),以及人体和环境交互形成的约束关系。直观上看,约束信息相比于外观信息而言,更复杂多样,对于网络而言学习难度更大,这会使得在外观信息充分的情况下,存在约束条件被忽视的可能性(模型会偷懒,不学习/使用约束信息)。基于此假设,作者引入了信息丢失的正则化手段,通过在训练过程中以一定的概率丢失关键点的外观信息,以此避免训练过程拟合外观信息而忽视约束信息。

Tips:能稳定带来收益的一个数据增强,对于Heatmap-based方法尤其必要,能极大程度上缓解Heatmap方法遇到遮挡时的关键点偏移问题,对于Regression-based方法也同样有效。
2. Unbiased Data Processing(UDP)
同属于COCO2020 冠军团队论文之一,上面那篇主打数据增强,而这一篇则是从消除数据误差的角度,指出大家过去的数据处理方式存在问题,无意中引入了误差。
Tips:能稳定带来收益的一个设计,在Heatmap-based和Regression-based方法上均亲测有效,推荐阅读
姿态估计经典论文 | 无偏数据处理UDP:魔鬼藏在细节里 - 知乎 (zhihu.com)
结构篇
ICCV 2021 | 利用在线知识蒸馏进行高效2D人体姿态估计
论文地址: https://arxiv.org/abs/2108.02092
Abstract:
我们提出了一个新的在线知识蒸馏框架OKDHP去对人体姿态估计模型进行提升。特别地,OKDHP训练了一个多分支网络,其中每个分支都被当做独立的学生模型,这里的教师不是显式存在的,而是通过加权集成多个分支的结果后形成的集成heatmap来扮演教师的作用,通过优化Pixel-wise KL Divergence损失来优化每个学生分支模型。整个训练过程被简化到了one-stage,不需要额外预训练的教师模型。我们在MPII和COCO上都证明了该方法的有效性。
主流的2D姿态估计方法大多数都是基于Hourglass Network[1](HG),典型的工作有[2],[3],[4]。其含有多个堆叠的Hourglass,通常有2-stack, 4-stack, 8-stack类型。后一个Hourglass将前一个Hourglass的结果作为输入,不断进行refine,直到结尾。8-stack的结果要明显好于4-stack,但是与之而来的问题就是计算量明显的增加。
FPD[5](CVPR 19')首先提出,利用传统的蒸馏(KD)方法,首先训一个8-stack HG作为teacher,选择一个4-stack HG作为student,然后进行KD。参考Fig. 1。
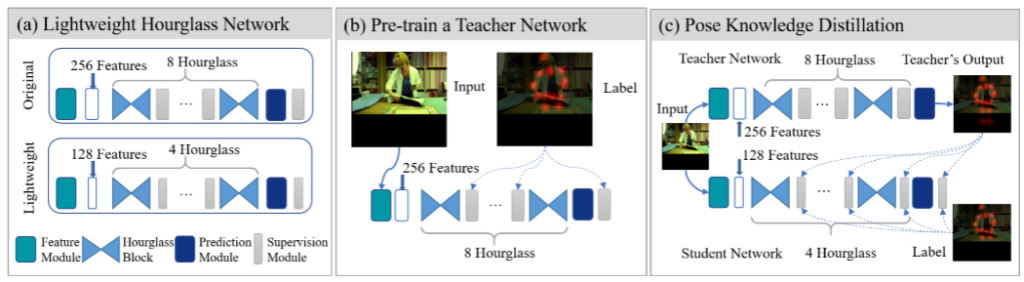
那么这篇工作明显存在着几点问题:
(1). 第一步训teacher,第二步训student,整体是一个two-stage的过程,较为繁琐。
(2). 如果要利用FPD训练一个8-stack HG的student,就需要找到一个比8-stack更高的model去作为teacher。堆叠更多的HG会存在性能收益递减,并且带来计算量直线上升。
(3). KD过程中同时使用Mean Squared Error(MSE)作为传统任务的监督loss和kd loss,训练时一个output同时针对两个target进行优化会带来明显的冲突。
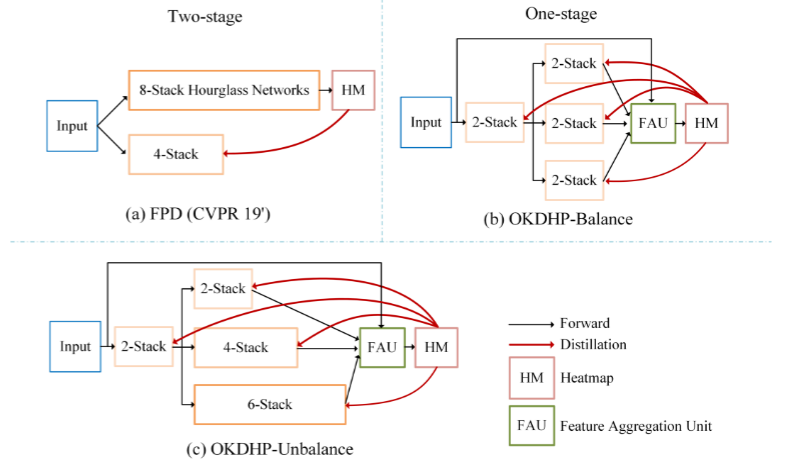
由以上的几个问题就引出了我们ICCV 2021的工作,我们首先提出了利用在线知识蒸馏的方法去对网络进行训练。用大白话来概括一下工作的几个核心:
(1). 我们提出了一个在线知识蒸馏的框架,即一个多分支结构。这里的teacher不是显式存在的,而是通过多个学生分支的结果经过了FAU的ensemble形成的,即established on the fly,我们利用ensemble得到的结果(拥有更高的准确率)来扮演teacher的角色,来KD每个的学生分支,即在Fig.2 (b)中的三个小分支。
具体来说就是,如果要得到一个4-stack HG的网络,FPD的方式如(a)所示,先训练一个8-stack,然后进行KD。而在我们的方法,如图(b),直接建立一个多分支网络(图中为3个分支),其中每个分支视为student,要得到一个4-stack HG,那么我们选择在前部share 2个stack(节约计算量),后面针对每一个branch,我们将剩下的2个stack HG独立出来,以保持diversity。三个分支产生的结果经过FAU进行ensemble,得到的ensemble heatmap再KD回每一个student分支。
我们的方法带来的直接的好处就是,整个的KD过程被简化到了one-stage,并且不需要手动的选择一个更高performance的teacher来进行KD。Online KD的方法直接训练完了之后,选择一个最好性能的分支,去除掉其他多余分支结构即可得到一个更高acc的目标HG网络。
那么从这里也可以直接看出我们的多分支网络更省计算量,粗略的算,FPD的方法总共会需要8+4=12个stack参与计算,我们的方法,只会有2x4=8个stack进行计算。
(针对diversity的问题提一下,在OKDDip[6]中就有提及,针对这样的一个多分支模型,每个分支之间的diversity是需要考虑的,对于每个分支,如果共享的stage过多,那么留给剩下分支的优化空间就会被明显缩小,分支之间在训练的过程中会显式的趋于同质化,进而带来的结果就是ensemble结果准确率的下降。与之相反,独立的HG数量越多也可以带来KD性能的提升,分支数量同理,详情请参考paper中的Table 7和8,这里不详细列出。我们在paper中将共享的HG数量设定为目标网络HG数量的一半,即目标网络8-stack,整个网络就共享4-stack。)
(2). 既然是一个多分支结构,那么每个分支的情况可不可以是adaptive的?既然在分支里更多的stack可以产生更好的heatmap,那么必然也就会带来ensemble结果的提升,进而KD的效果就会更好。于是针对(b)的这种每个分支都是一样的balance的结构,我们更进一步提出了unbalance结构。
具体的来说,要KD得到一个4-stack HG,即Fig.2 (c)中的第一个branch,2+2=4个stack的主分支,通过在辅助分支堆叠更多的HG来产生更好的ensemble结果,这里就是第二个分支是2+4=6个stack,第三个分支2+6=8个stack的情况。
在不考虑训练计算量的情况下,在部署时移除辅助分支,相比于balance结构,可以得到更好的main branch,即目标的4-stack HG。
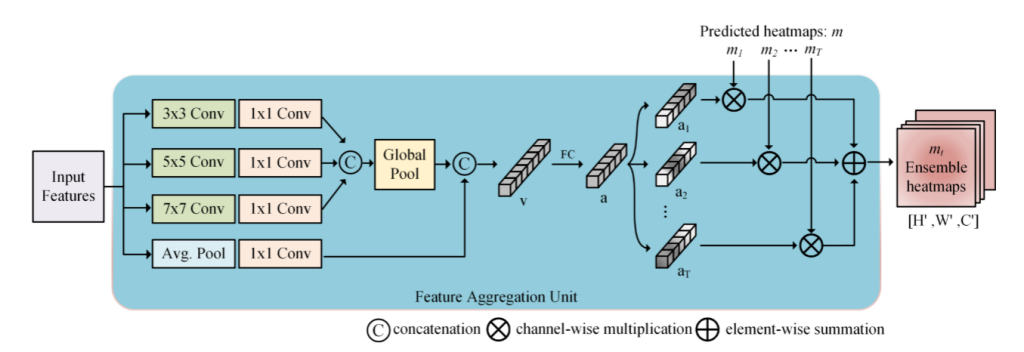
(3). 这里的FAU,即Feature Aggregation Unit,是用来对每个分支产生的结果进行一个带有weight的channel-wise的ensemble。即将每个heatmap按照生成的权重进行集成。具体的结构如Fig.3所示。



Comments | NOTHING